Dynamic Resolution Gundam Mode
Deepseek-ocr Gundam intelligently mixes 640×640 and 1024×1024 crops so dense invoices, schematics, and multi-column magazines stay legible without inflating context windows.
Deepseek ocr compresses visual evidence into dense tokens so builders can reconstruct text, layout, and semantics in one pass. The open-source release merges OCR, grounding, and reasoning, letting you stream markdown, JSON, or richly annotated prose from invoices, manufacturing logs, and multilingual magazines without compromising data privacy.
Teams deploy deepseekocr with vLLM, Transformers, and edge runtimes to automate compliance audits, ingest knowledge bases, and trigger robotic process automation. With deepseek-ocr you can orchestrate document intelligence pipelines that stay explainable, scalable, and tailored to more than 90 languages.
Hugging Face analytics confirm deepseek ocr is the default playground for engineers validating multimodal extraction before deploying to production.
Repositories cataloging deepseekocr and deepseek-ocr techniques attract hundreds of millions of views, highlighting a fast-maturing integration ecosystem.
Vision token compression keeps deepseek-ocr near lossless while trimming GPU costs so you can scale document queues without sacrificing fidelity.
Dynamic resolution pipelines let deepseek ocr decode Latin, CJK, and RTL layouts, powering passports, pharmaceutical inserts, and compliance archives.
Experiment with the DeepSeek-OCR Hugging Face Space to parse receipts, dense PDFs, tables, and multilingual assets. The embedded lab mirrors the official deepseek ocr playground so you can test deepseekocr prompts without leaving deepseekocr.org.
Load sample invoices, upload contract scans, or paste screenshots to compare deepseek-ocr output with legacy OCR engines. For the best experience, open the demo in full screen and adjust the compression slider to watch how deepseek ocr balances quality with speed.
See how deepseek ocr and its deepseek-ocr Gundam variant keep commercial invoices, multilingual brochures, scientific diagrams, and e-commerce receipts aligned and intelligible even under aggressive compression.

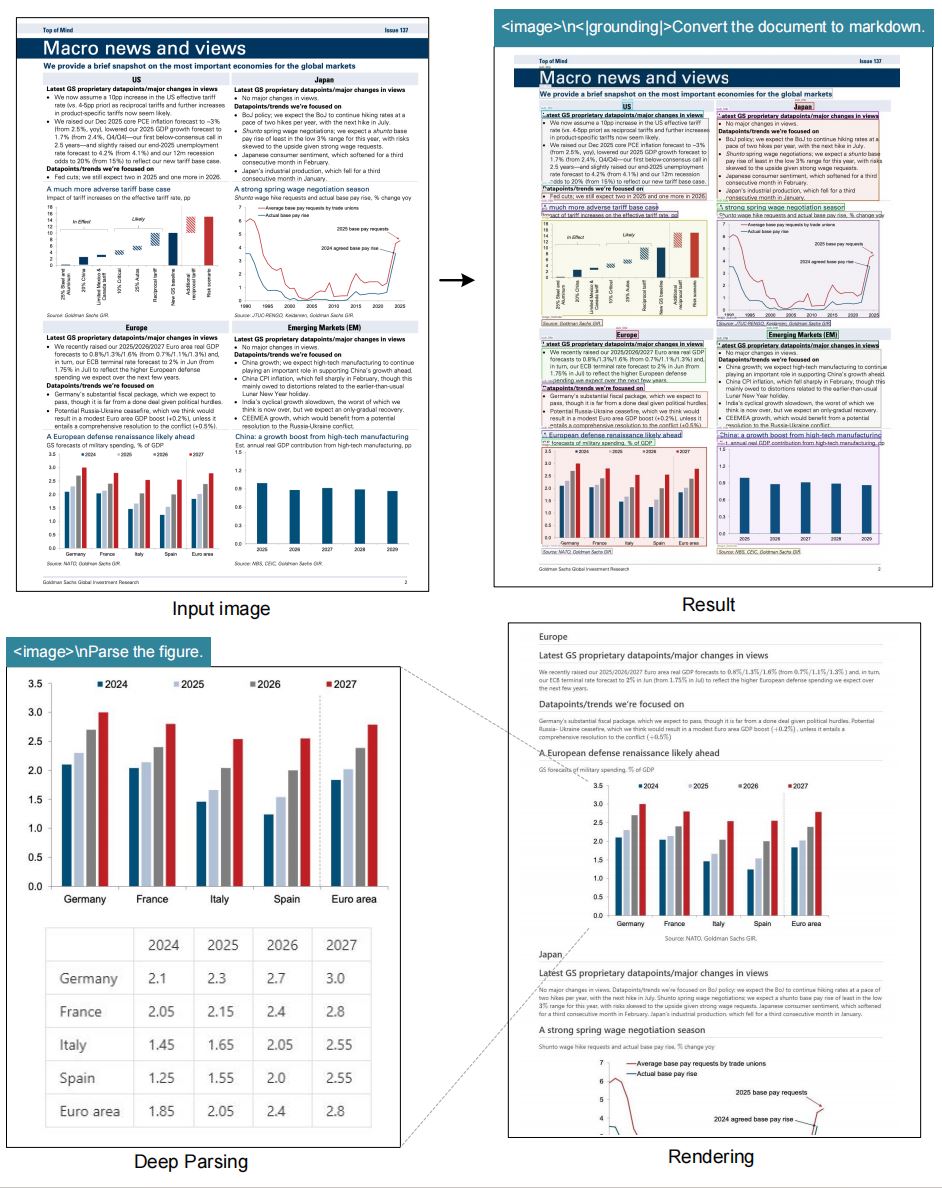


The deepseek ocr stack fuses dynamic vision tokens with LLM reasoning, delivering accuracy that classical engines struggle to match.
Deepseek-ocr Gundam intelligently mixes 640×640 and 1024×1024 crops so dense invoices, schematics, and multi-column magazines stay legible without inflating context windows.
Craft prompts such as “<|grounding|>Convert the document to markdown” or “Locate <|ref|>invoice total<|/ref|>” to recover markdown, HTML, JSON, or targeted spans in one deepseek ocr call.
Vision token compression keeps inference throughput high—up to ~2500 tokens/s on A100 40G via vLLM—while maintaining deepseekocr readability for long context PDFs.
Released under the MIT license, deepseek-ocr invites pull requests, localized documentation, and community fine-tunes across academic, enterprise, and government workloads.
Benchmark runs on OmniDocBench show that deepseek ocr keeps multi-header tables aligned, mitigating the column drift that plagues template-driven OCR services.
Run with vLLM, Transformers, or custom pipelines across CUDA 11.8+ environments. Tutorials cover local workstations, managed Kubernetes, and serverless GPU bursts.
Blend deepseek ocr with retrieval-augmented generation, document understanding agents, or downstream analytics to minimize manual review. The deepseekocr roadmap continues to expand—watch for new deepseek-ocr checkpoints that tighten latency while raising accuracy on low-resolution scans.
Data points from GitHub, Hugging Face, and community lab tests reinforce the reliability of deepseekocr across global workloads.
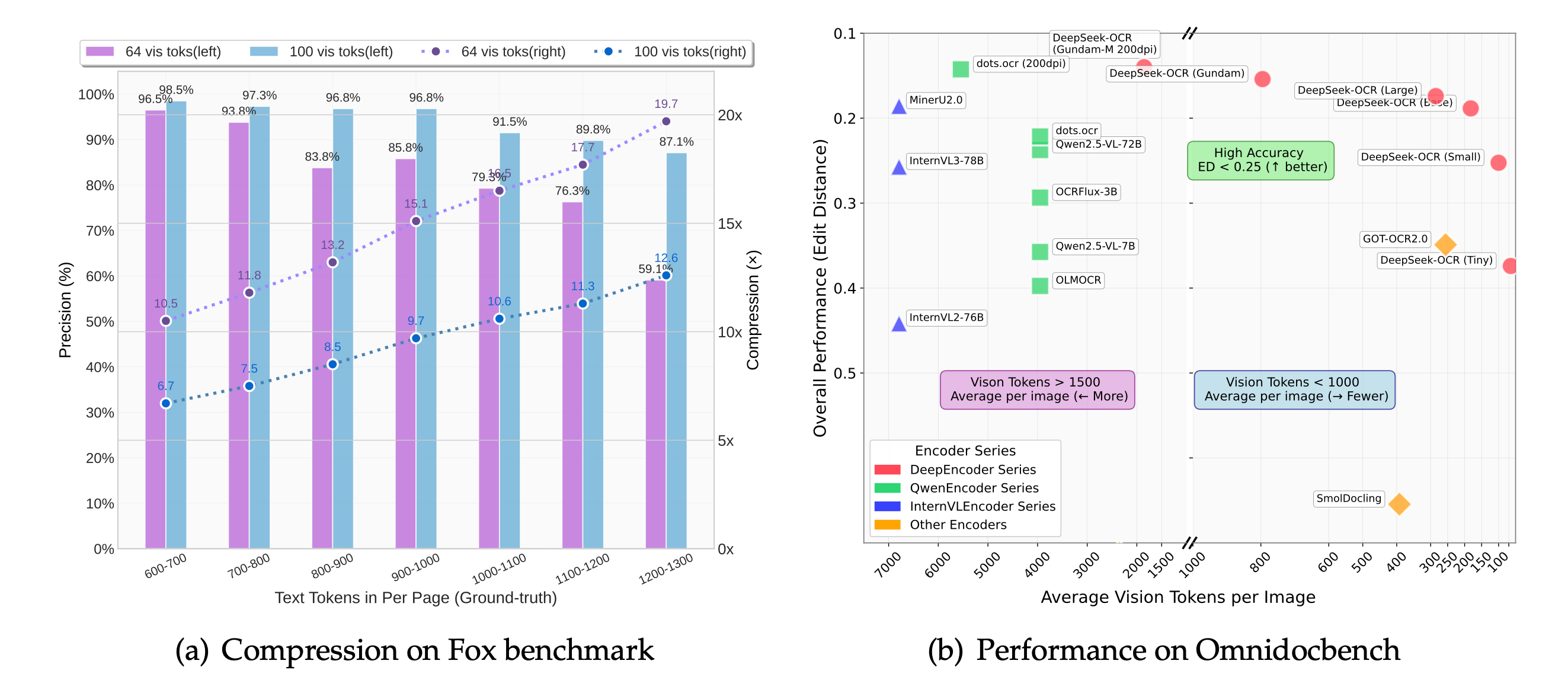
Deepseek ocr compresses vision tokens at 10× with negligible loss. Even at 20×, 60% accuracy is retained—ideal for cost-sensitive ingestion pipelines.
Hugging Face reports 22.9M monthly visits for deepseek-ocr assets, with GitHub logging 471.49M unique interactions, underscoring production readiness.
LLM-centric reasoning allows deepseekocr to narrate diagrams, annotate receipts, and label bounding boxes without separate OCR + NLP stacks.
Adopt privacy reviews for sensitive deployments—community feedback highlights the importance of minimizing hallucinations for legal and healthcare records.
Because deepseek ocr operates as a vision-language model, benchmark interpretation should include prompt engineering and post-processing metrics. Monitor deepseekocr precision alongside manual sampling to guarantee that deepseek-ocr rollouts meet regulatory expectations.
From developer sandboxing to enterprise-grade document intelligence, deepseek ocr adapts quickly.
Convert image-based PDFs into searchable markdown, extract footnotes, and auto-summarize pages with deepseekocr prompts plus RAG toolchains. Deepseek ocr hands you normalized text, bounding boxes, and visual cues so downstream search indexes stay trustworthy.
Combine deepseek-ocr with n8n or custom HTTP nodes to trigger downstream GPT, Claude, or Gemini reasoning steps while preserving structured table outputs. The result is an automated chain where deepseek ocr handles precision extraction and bots manage decisions.
Deploy the MIT-licensed weights in private data centers so confidential contracts, ID cards, or lab notebooks stay under your governance. Deepseekocr checkpoints are easy to quantize, enabling air-gapped deepseek-ocr environments that satisfy auditors.
Educators archive vintage magazines and handwritten notes by mixing deepseek ocr with manual review, drastically reducing transcription cycles. Librarians lean on deepseekocr metadata to drive discovery portals and digital humanities projects.
Telemetry from Hugging Face, GitHub, and the broader developer community highlights how deepseek ocr is evolving from a research release into a production OCR backbone.
Hugging Face reports 22.9M monthly sessions on the official demo, while GitHub projects referencing deepseekocr and deepseek-ocr have passed 471.49M views. The appetite for compression-aware OCR shows that developers want modern tooling that preserves layout context without ballooning GPU costs.
Each new checkpoint continues the “context optical compression” agenda: deepseek ocr hits near-lossless accuracy at 10× compression and retains roughly 60% fidelity at 20×. That lets product teams run larger backlogs with fewer resources while still returning formatted text that downstream systems can trust.
Hacker News threads dissect the deepseek-ocr whitepaper, debating how semantic token pooling compares with traditional OCR heuristics. On Reddit’s r/LocalLLaMA, r/MachineLearning, and automation forums you’ll find tutorials that wire deepseek ocr into n8n, Airflow, and bespoke ETL jobs.
Operators praise the way deepseekocr handles complex tables and handwriting but caution against blind trust—quality gates, JSON schema validation, and spot audits remain best practice. The shared lesson: pair deepseek-ocr with lightweight review workflows to eliminate hallucinations before data lands in CRMs or BI systems.
Analysts compare deepseek ocr with Azure Document Intelligence, Google Vision API, and ABBYY to gauge when open models can displace commercial SaaS. Benchmarks from OmniAI and AI Advances show the gap closing quickly as deepseekocr improves table alignment and low-light robustness.
Enterprise case studies highlight deepseek-ocr in compliance archives, logistics receipts, and pharmaceutical labeling. Teams mix vLLM microservices, FastAPI, and n8n templates so deepseek ocr outputs feed RAG search, customer support copilots, or robotic process automation bots with minimal glue code.
Follow these steps to embed deepseekocr into your stack.
Clone github.com/deepseek-ai/DeepSeek-OCR, create a Python 3.12 environment, and install torch==2.6.0, vllm==0.8.5, and project requirements. Optional: add flash-attn for fast inference.
For air-gapped deployments, run pip download to stage wheels, mirror model weights inside your artifact store, and script checksum validation so deepseek-ocr remains reproducible across nodes.
Use run_dpsk_ocr_image.py for streaming image outputs or run_dpsk_ocr_pdf.py for long-form PDFs. Transformers users can call model.infer(... test_compress=True) to evaluate compression.
Production stacks often wrap deepseek ocr with vLLM microservices or a FastAPI gateway; autoscale GPU workers, capture metrics, and expose health endpoints so deepseekocr remains predictable under load.
Adopt prompt templates like “<image>\n<|grounding|>Convert the document to markdown.” for layout fidelity or “Locate <|ref|>tax rate<|/ref|>” to capture targeted values.
Add layout hints (“preserve multi-column format”) and language cues (“respond in English”) so deepseekocr returns consistent structures. Store proven deepseek-ocr prompts in version control to align teams.
Leverage quality checks for hallucinations, monitor compression ratios, and iterate with community issue trackers to keep deepseek ocr performance high.
Pump metrics to Grafana or Prometheus—track OCR success rates, average compression targets, and human review percentages so deepseek-ocr decisions stand up to audits.
Deepseek-ocr builds on open community benchmarks such as GOT-OCR2.0 and MinerU, with acknowledgements to Vary, PaddleOCR, OneChart, Slow Perception, Fox, and OmniDocBench for publicly available evaluation suites.
Teams augment these corpora with public scans from Anna’s Archive, legal filings, and enterprise PDFs to create fine-tunes that mirror their domain. Feeding the model long-tail samples keeps deepseek-ocr robust as data drifts.
Enable test_compress=True, request JSON schema validation, and cross-check extractions with rule-based regex as a final guardrail. For critical workloads, pair deepseek ocr with human-in-the-loop review.
Community playbooks recommend a two-stage flow—run deepseekocr, then summarize with an LLM while logging confidence scores and diff visualizations. Anything below threshold routes to humans instead of entering production systems.
Yes. The Tiny and Small variants run comfortably on 12GB VRAM cards, while the Base and Gundam models benefit from 24GB+. Linux, Windows, and macOS guides from the community cover installation.
For edge devices, quantize the Tiny checkpoint and export through TensorRT-LLM or ONNX Runtime to keep deepseek ocr under strict power budgets while serving kiosks, industrial scanners, or robotics.
Open pull requests on the official GitHub repository or share localized prompts via Hugging Face discussions. deepseekocr prioritizes bilingual (English & Simplified Chinese) documentation updates.
Share scripts, Dockerfiles, and workflow guides through GitHub, Hugging Face, or Reddit so the wider deepseek-ocr community can replicate success and accelerate deployment timelines.