동적 해상도 Gundam 모드
deepseek-ocr Gundam은 640×640과 1024×1024 크롭을 지능적으로 혼합해 밀집 인보이스, 도면, 다단 매거진을 컨텍스트 길이를 늘리지 않고도 읽기 쉽게 유지합니다.
deepseek ocr는 시각 증거를 고밀도 토큰으로 압축해 한 번의 추론으로 텍스트, 레이아웃, 의미를 재구성할 수 있도록 합니다. 오픈소스 릴리스는 OCR, 그라운딩, 추론을 결합해 청구서, 제조 로그, 다국어 잡지에서 개인정보를 보호한 채 Markdown, JSON, 주석 텍스트를 스트리밍합니다.
팀은 deepseekocr를 vLLM, Transformers, 엣지 런타임과 함께 배포해 컴플라이언스 감사 자동화, 지식 베이스 적재, RPA 트리거를 구현합니다. deepseek-ocr로 설명 가능하고 확장 가능하며 90여 개 언어에 맞춘 문서 인텔리전스 파이프라인을 구축할 수 있습니다.
Hugging Face 분석에 따르면 deepseek ocr는 프로덕션 이전에 멀티모달 추출을 검증하는 엔지니어의 기본 실험장이 되었습니다.
deepseekocr와 deepseek-ocr 기술을 모은 저장소는 수억 건의 조회수를 기록하며 빠르게 성숙하는 통합 생태계를 보여줍니다.
시각 토큰 압축은 deepseek-ocr의 손실을 최소화하는 동시에 GPU 비용을 줄여, 품질을 유지하며 문서 큐를 확장할 수 있게 합니다.
동적 해상도 파이프라인으로 deepseek ocr는 라틴, CJK, RTL 레이아웃을 해독해 여권, 의약품 설명서, 컴플라이언스 아카이브를 처리합니다.
DeepSeek-OCR Hugging Face Space에서 영수증, 고밀도 PDF, 표, 다국어 자료를 직접 실험해 보세요. 내장된 랩은 공식 deepseek ocr 플레이그라운드와 동일하여 사이트를 벗어나지 않고 프롬프트를 테스트할 수 있습니다.
샘플 인보이스를 불러오고 계약 스캔을 업로드하거나 스크린샷을 붙여 deepseek-ocr 출력과 기존 OCR 엔진을 비교하세요. 전체 화면으로 열고 압축 슬라이더를 조정하면 deepseek ocr가 품질과 속도를 어떻게 균형 잡는지 확인할 수 있습니다.
deepseek ocr와 deepseek-ocr Gundam 변형이 상업 인보이스, 다국어 브로셔, 과학 다이어그램, 이커머스 영수증을 강한 압축 하에서도 정렬되고 읽기 쉬운 상태로 유지하는 모습을 살펴보세요.



deepseek ocr 스택은 동적 비전 토큰과 LLM 추론을 결합해 전통 엔진이 따라오기 힘든 정확도를 제공합니다.
deepseek-ocr Gundam은 640×640과 1024×1024 크롭을 지능적으로 혼합해 밀집 인보이스, 도면, 다단 매거진을 컨텍스트 길이를 늘리지 않고도 읽기 쉽게 유지합니다.
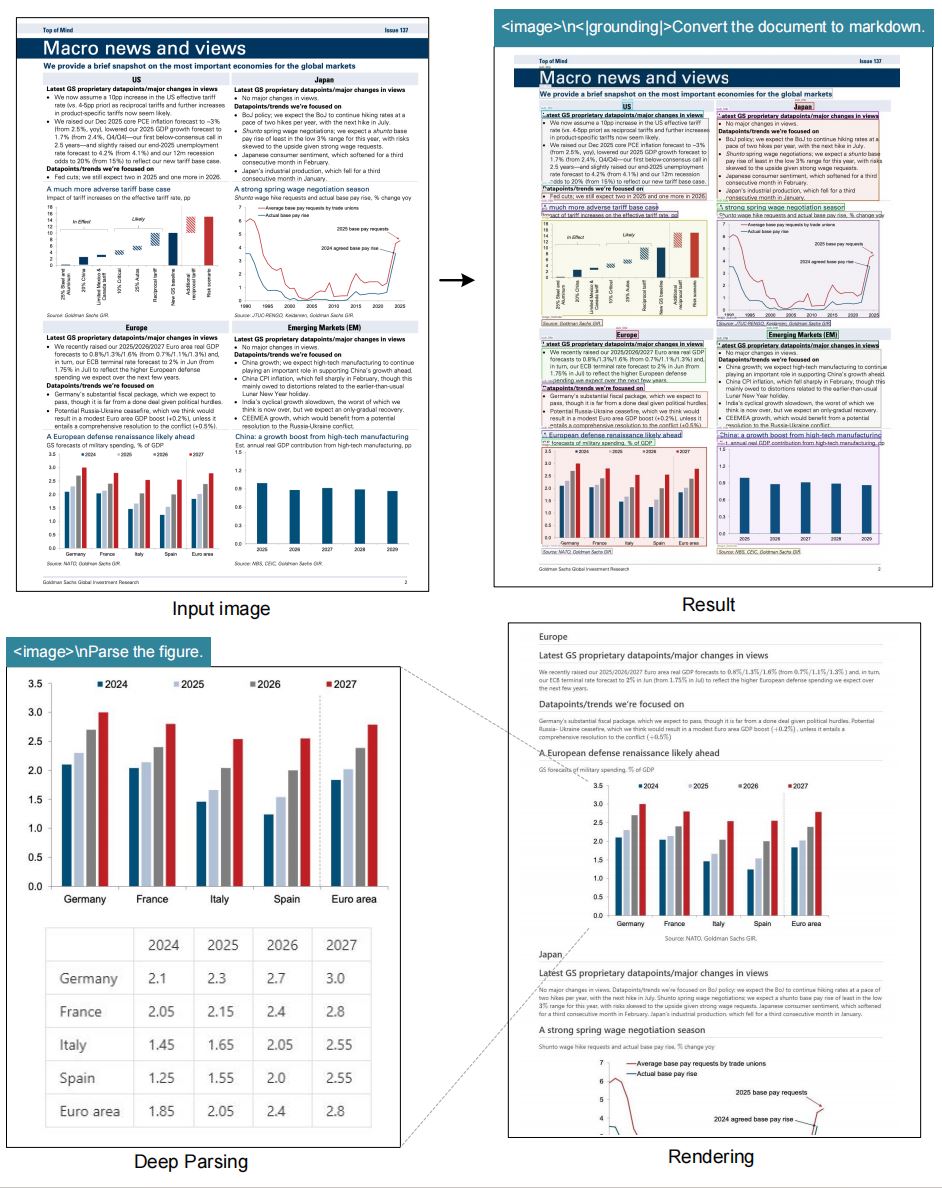
"<|grounding|>Convert the document to markdown" 또는 "Locate <|ref|>invoice total<|/ref|>" 같은 프롬프트를 작성해 한 번의 deepseek ocr 호출로 Markdown, HTML, JSON, 특정 영역을 받아보세요.
시각 토큰 압축은 추론 처리량을 높게 유지합니다 — vLLM을 사용한 A100 40G에서 초당 약 2500 토큰 — 동시에 긴 PDF에서도 deepseekocr의 가독성을 보장합니다.
MIT 라이선스로 공개된 deepseek-ocr는 학계, 기업, 공공 워크로드 전반에서 Pull Request, 현지화 문서, 커뮤니티 파인튜닝을 환영합니다.
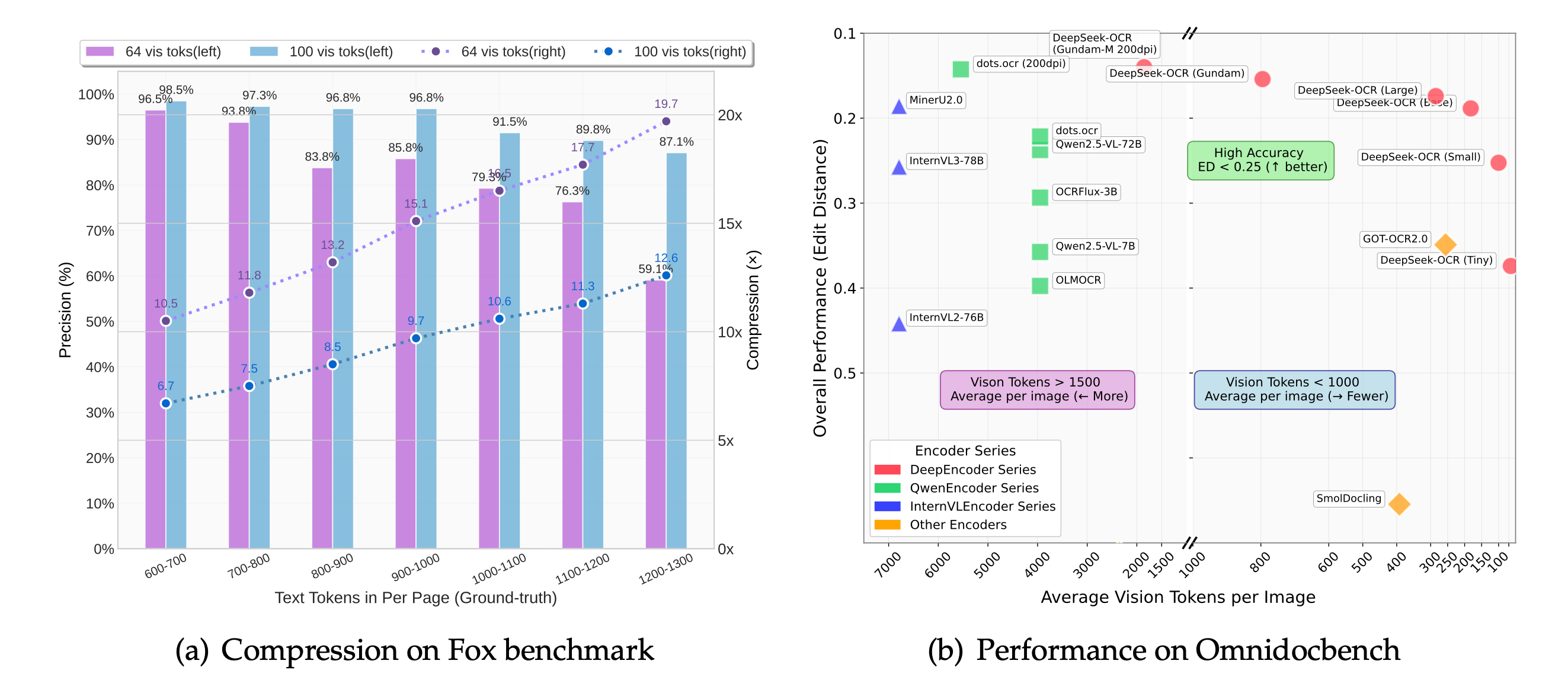
OmniDocBench 벤치마크는 deepseek ocr가 다중 헤더 표의 정렬을 유지해 템플릿 기반 OCR 서비스에서 흔한 열 이동을 줄여준다는 점을 보여줍니다.
vLLM, Transformers 또는 커스텀 파이프라인을 통해 CUDA 11.8+ 환경 어디에서나 실행할 수 있습니다. 로컬 워크스테이션, 관리형 Kubernetes, 서버리스 GPU 버스트에 대한 튜토리얼도 마련되어 있습니다.
deepseek ocr를 RAG, 문서 이해 에이전트, 후속 분석과 결합해 수동 검토를 최소화하세요. deepseekocr 로드맵은 계속 확장 중이며, 지연 시간을 줄이고 저해상도 스캔에서 정확도를 높이는 새로운 deepseek-ocr 체크포인트가 곧 공개됩니다.
GitHub, Hugging Face, 커뮤니티 랩 데이터가 deepseekocr의 글로벌 워크로드 신뢰성을 뒷받침합니다.
deepseek ocr는 10× 압축에서도 손실이 거의 없습니다. 20×에서도 정확도 60 %를 유지해 비용 민감한 수집 파이프라인에 적합합니다.
Hugging Face는 deepseek-ocr 자산의 월간 방문이 22.9 M에 달한다고, GitHub는 471.49 M의 고유 상호작용을 기록했다고 보고하여 프로덕션 준비성을 보여줍니다.
LLM 중심 추론 덕분에 deepseekocr는 개별 OCR+NLP 스택 없이도 다이어그램 설명, 영수증 주석, 바운딩 박스 라벨링을 수행합니다.
민감한 배포에서는 개인정보 검토를 수행하세요. 커뮤니티 피드백은 법률 및 의료 기록에서 환각을 줄이는 것이 중요하다고 강조합니다.
deepseek ocr는 비전-언어 모델로 동작하므로 벤치마크 해석에는 프롬프트 엔지니어링과 후처리 지표를 포함해야 합니다. deepseekocr 정확도를 수동 샘플링과 함께 모니터링해 deepseek-ocr 배포가 규제 요구를 충족하도록 하세요.
개발자 샌드박스부터 엔터프라이즈 문서 인텔리전스까지 deepseek ocr는 빠르게 적응합니다.
이미지 PDF를 검색 가능한 Markdown으로 변환하고 deepseekocr 프롬프트와 RAG 툴체인으로 각주를 추출하며 페이지 요약을 자동화하세요. deepseek ocr는 정규화된 텍스트와 바운딩 박스, 시각 힌트를 제공해 후속 검색 인덱스의 신뢰성을 유지합니다.
deepseek-ocr를 n8n 또는 커스텀 HTTP 노드와 연결해 GPT, Claude, Gemini 추론 단계를 호출하면서 구조화된 테이블 출력을 유지하세요. deepseek ocr가 정밀 추출을 맡고 봇이 의사결정을 처리하는 자동화 체인을 완성할 수 있습니다.
MIT 라이선스 가중치를 프라이빗 데이터 센터에 배포해 기밀 계약, 신분증, 연구 노트를 자체 거버넌스로 보호하세요. deepseekocr 체크포인트는 양자화가 쉬워 감사에 대응하는 격리된 deepseek-ocr 환경을 만들 수 있습니다.
교육 기관은 deepseek ocr와 수동 검토를 결합해 오래된 잡지와 필기 노트를 아카이브하고 전사 사이클을 크게 줄입니다. 사서들은 deepseekocr 메타데이터를 활용해 검색 포털과 디지털 휴머니티 프로젝트를 강화합니다.
Hugging Face, GitHub, 개발자 커뮤니티의 텔레메트리가 deepseek ocr가 연구 릴리스에서 프로덕션 OCR 백본으로 성장하는 과정을 보여줍니다.
Hugging Face는 공식 데모 월간 세션이 22.9 M에 달한다고, deepseekocr와 deepseek-ocr를 언급한 GitHub 프로젝트 조회수가 471.49 M을 넘었다고 밝혔습니다. 압축 인지형 OCR에 대한 수요는 레이아웃 컨텍스트를 유지하면서 GPU 비용을 억제하려는 개발자 니즈를 보여줍니다.
새 체크포인트는 "컨텍스트 광학 압축" 전략을 이어가며 deepseek ocr는 10×에서 거의 손실 없이, 20×에서도 약 60 %의 정확도를 유지합니다. 덕분에 제품 팀은 리소스를 아끼면서도 더 큰 백로그를 처리하고, 신뢰할 수 있는 포맷의 텍스트를 제공할 수 있습니다.
Hacker News 스레드는 deepseek-ocr 백서를 분석하며 의미 토큰 풀링과 전통 OCR 휴리스틱을 비교합니다. Reddit r/LocalLLaMA, r/MachineLearning, 자동화 포럼에는 deepseek ocr를 n8n, Airflow, 맞춤 ETL에 연결하는 튜토리얼이 다수 공유됩니다.
운영자는 deepseekocr가 복잡한 표와 필기체를 잘 다룬다고 평가하지만, 맹신은 금물이라며 품질 게이트, JSON 스키마 검증, 표본 감사가 여전히 최선의 관행이라고 조언합니다. 결론은 CRM이나 BI에 데이터를 넣기 전에 경량 리뷰 워크플로를 결합해 환각을 제거하라는 것입니다.
애널리스트는 deepseek ocr를 Azure Document Intelligence, Google Vision API, ABBYY와 비교해 오픈 모델이 상용 SaaS를 대체할 시점을 가늠합니다. OmniAI와 AI Advances 벤치마크는 deepseekocr가 표 정렬과 저조도 강인성을 향상시키며 격차가 빠르게 줄고 있음을 보여줍니다.
기업 사례는 컴플라이언스 아카이브, 물류 영수증, 제약 라벨링에서 deepseek-ocr를 조명합니다. 팀은 vLLM 마이크로서비스, FastAPI, n8n 템플릿을 조합해 deepseek ocr 출력이 RAG 검색, 고객 지원 코파일럿, RPA 봇으로 최소한의 글루 코드만으로 흘러가도록 합니다.
다음 단계를 따라 deepseekocr를 스택에 통합하세요.
github.com/deepseek-ai/DeepSeek-OCR을 클론하고 Python 3.12 환경을 만든 뒤 torch==2.6.0, vllm==0.8.5, 프로젝트 요구 사항을 설치하세요. 필요한 경우 flash-attn으로 추론 속도를 높일 수 있습니다.
격리 환경에서는 pip download로 휠을 준비하고, 모델 가중치를 아티팩트 저장소에 미러링하며, 체크섬 검증을 스크립팅해 deepseek-ocr가 노드 간 재현성을 유지하도록 합니다.
이미지 스트리밍에는 run_dpsk_ocr_image.py, 장문 PDF에는 run_dpsk_ocr_pdf.py를 사용하세요. Transformers 사용자는 model.infer(... test_compress=True)로 압축을 평가할 수 있습니다.
프로덕션 스택은 deepseek ocr를 vLLM 마이크로서비스 또는 FastAPI 게이트웨이로 래핑하는 경우가 많습니다. GPU 워커를 자동 확장하고, 메트릭을 수집하며, 헬스 엔드포인트를 노출해 deepseekocr가 부하에도 안정적으로 동작하도록 하세요.
"<image>\n<|grounding|>Convert the document to markdown."과 같은 템플릿으로 레이아웃을 유지하고, "Locate <|ref|>tax rate<|/ref|>"로 특정 값을 추출하세요.
"preserve multi-column format"과 같은 레이아웃 힌트, "respond in English"와 같은 언어 힌트를 추가해 deepseekocr가 일관된 구조를 반환하도록 합니다. 검증된 deepseek-ocr 프롬프트는 버전 관리로 팀 간 공유하세요.
환각을 막기 위한 품질 검사를 적용하고, 압축 비율을 모니터링하며, 커뮤니티 이슈 트래커와 협력해 deepseek ocr 성능을 유지하세요.
Grafana나 Prometheus로 메트릭을 전송해 OCR 성공률, 평균 압축 목표, 인간 검토 비율을 추적하면 deepseek-ocr 의사결정이 감사 기준을 충족합니다.
deepseek-ocr는 GOT-OCR2.0, MinerU 등 커뮤니티 오픈 벤치마크를 기반으로 하며, Vary, PaddleOCR, OneChart, Slow Perception, Fox, OmniDocBench의 공개 평가 세트에 감사를 표합니다.
팀은 Anna's Archive 공개 스캔, 법원 문서, 엔터프라이즈 PDF를 추가해 도메인에 맞춘 파인튜닝을 수행합니다. 롱테일 샘플을 공급하면 데이터 변동에도 deepseek-ocr의 견고성이 유지됩니다.
test_compress=True를 활성화하고 JSON 스키마 검증을 요청하며, 마지막 단계에서 정규 표현식으로 추출 결과를 비교하세요. 핵심 업무에는 사람 검토를 결합하는 것이 좋습니다.
커뮤니티 플레이북은 2단계 흐름을 권장합니다. 먼저 deepseekocr를 실행하고, 이후 LLM으로 요약하면서 신뢰도 점수와 차이 시각화를 기록합니다. 임계값 미만 결과는 사람이 검토하도록 라우팅해 프로덕션 시스템 유입을 방지하세요.
가능합니다. Tiny와 Small 모델은 12 GB VRAM에서도 원활히 동작하며, Base와 Gundam은 24 GB 이상이 있으면 좋습니다. Linux, Windows, macOS 설치 가이드가 커뮤니티에 공유되어 있습니다.
엣지 디바이스에서는 Tiny 체크포인트를 양자화하고 TensorRT-LLM 또는 ONNX Runtime으로 내보내면, 키오스크나 산업용 스캐너, 로보틱스에서도 낮은 전력으로 deepseek ocr를 제공할 수 있습니다.
공식 GitHub 저장소에 Pull Request를 올리고, Hugging Face 토론에서 현지화된 프롬프트를 공유하세요. deepseekocr는 영어와 간체 중국어 문서 업데이트를 우선합니다.
스크립트, Dockerfile, 워크플로 가이드를 GitHub, Hugging Face, Reddit에 공유해 deepseek-ocr 커뮤니티가 성공을 재현하고 배포 일정을 앞당길 수 있도록 돕습니다.