Dynamischer Auflösungsmodus Gundam
Deepseek-ocr Gundam mischt intelligent 640×640- und 1024×1024-Ausschnitte, damit dichte Rechnungen, Schaltpläne und mehrspaltige Magazine lesbar bleiben, ohne die Kontextfenster aufzublähen.
Deepseek ocr komprimiert visuelle Evidenz in dichte Token, sodass Teams Text, Layout und Semantik in einem Durchgang rekonstruieren können. Die Open-Source-Veröffentlichung vereint OCR, Grounding und Reasoning, sodass Sie Markdown, JSON oder reich annotierten Fließtext aus Rechnungen, Fertigungsprotokollen und mehrsprachigen Magazinen streamen können, ohne die Datensouveränität zu gefährden.
Teams setzen deepseekocr gemeinsam mit vLLM, Transformers und Edge-Runtimes ein, um Compliance-Prüfungen zu automatisieren, Wissensbasen einzulesen und Robotic-Process-Automation anzustoßen. Mit deepseek-ocr orchestrieren Sie Dokumenten-Intelligence-Pipelines, die erklärbar, skalierbar und auf mehr als 90 Sprachen zugeschnitten bleiben.
Hugging Face Analytics bestätigen, dass deepseek ocr der Standardspielplatz für Ingenieur:innen ist, die multimodale Extraktion validieren, bevor sie in Produktion gehen.
Repositorys, die deepseekocr und deepseek-ocr Techniken katalogisieren, verzeichnen Hunderte Millionen Aufrufe und unterstreichen ein schnell reifendes Integrationsökosystem.
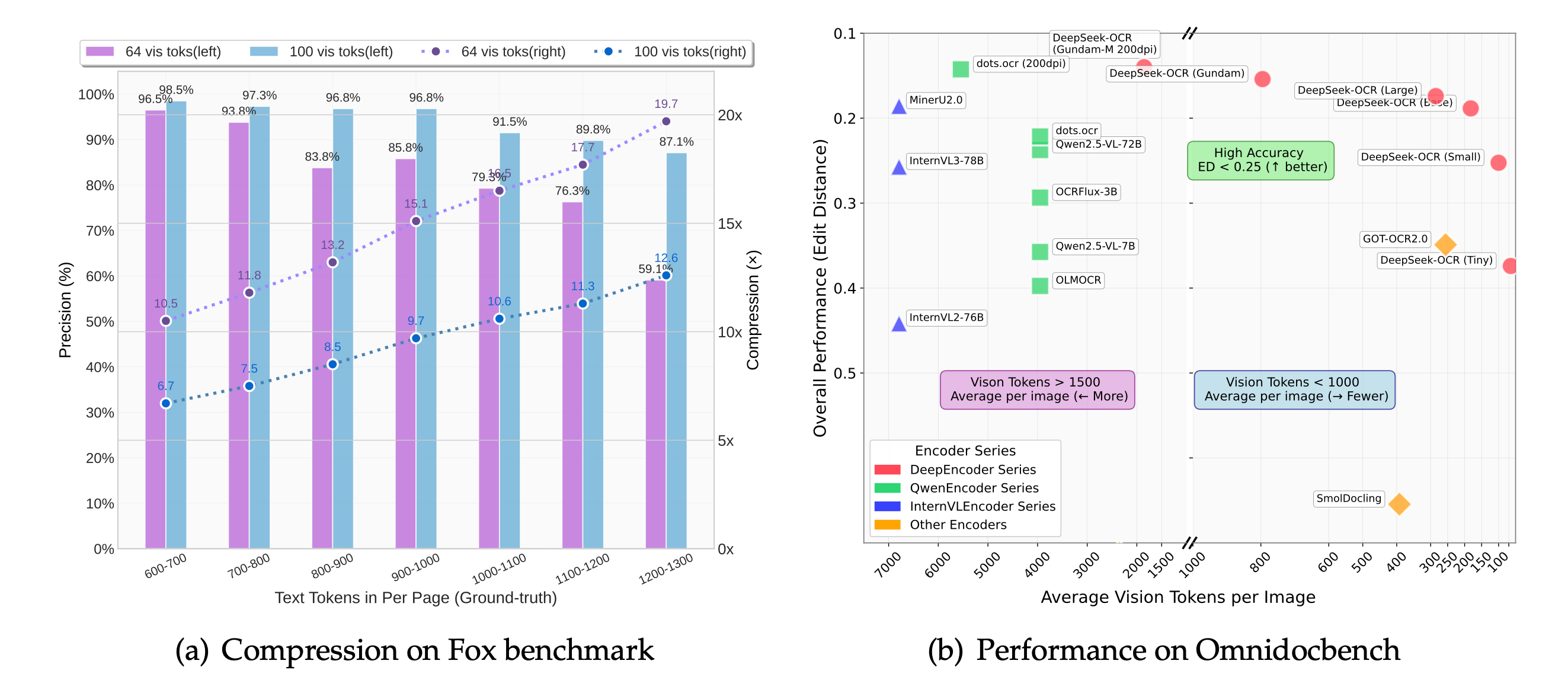
Die Kompression visueller Token hält deepseek-ocr nahezu verlustfrei und reduziert zugleich GPU-Kosten, sodass Sie Dokumentenschlangen skalieren können, ohne auf Präzision zu verzichten.
Dynamische Auflösungspipelines ermöglichen deepseek ocr die Dekodierung von lateinischen, CJK- und RTL-Layouts und versorgen Reisepässe, Beipackzettel und Compliance-Archive.
Experimentieren Sie im DeepSeek-OCR Hugging-Face-Space mit Quittungen, dichten PDFs, Tabellen und mehrsprachigen Assets. Das eingebettete Labor spiegelt den offiziellen deepseek ocr Playground, sodass Sie deepseekocr Prompts testen können, ohne deepseekocr.org zu verlassen.
Laden Sie Musterrechnungen, laden Sie Vertragsscans hoch oder fügen Sie Screenshots ein, um deepseek-ocr Ausgaben mit klassischen OCR-Engines zu vergleichen. Öffnen Sie die Demo idealerweise im Vollbild und passen Sie den Kompressionsregler an, um zu sehen, wie deepseek ocr Qualität und Geschwindigkeit ausbalanciert.
Sehen Sie, wie deepseek ocr und die deepseek-ocr Gundam Variante Handelsrechnungen, mehrsprachige Broschüren, wissenschaftliche Diagramme und E-Commerce-Belege selbst unter starker Kompression kohärent und lesbar halten.



Der deepseek ocr Stack kombiniert dynamische Vision-Token mit LLM-Reasoning und liefert Genauigkeit, mit der klassische Engines kaum mithalten.
Deepseek-ocr Gundam mischt intelligent 640×640- und 1024×1024-Ausschnitte, damit dichte Rechnungen, Schaltpläne und mehrspaltige Magazine lesbar bleiben, ohne die Kontextfenster aufzublähen.
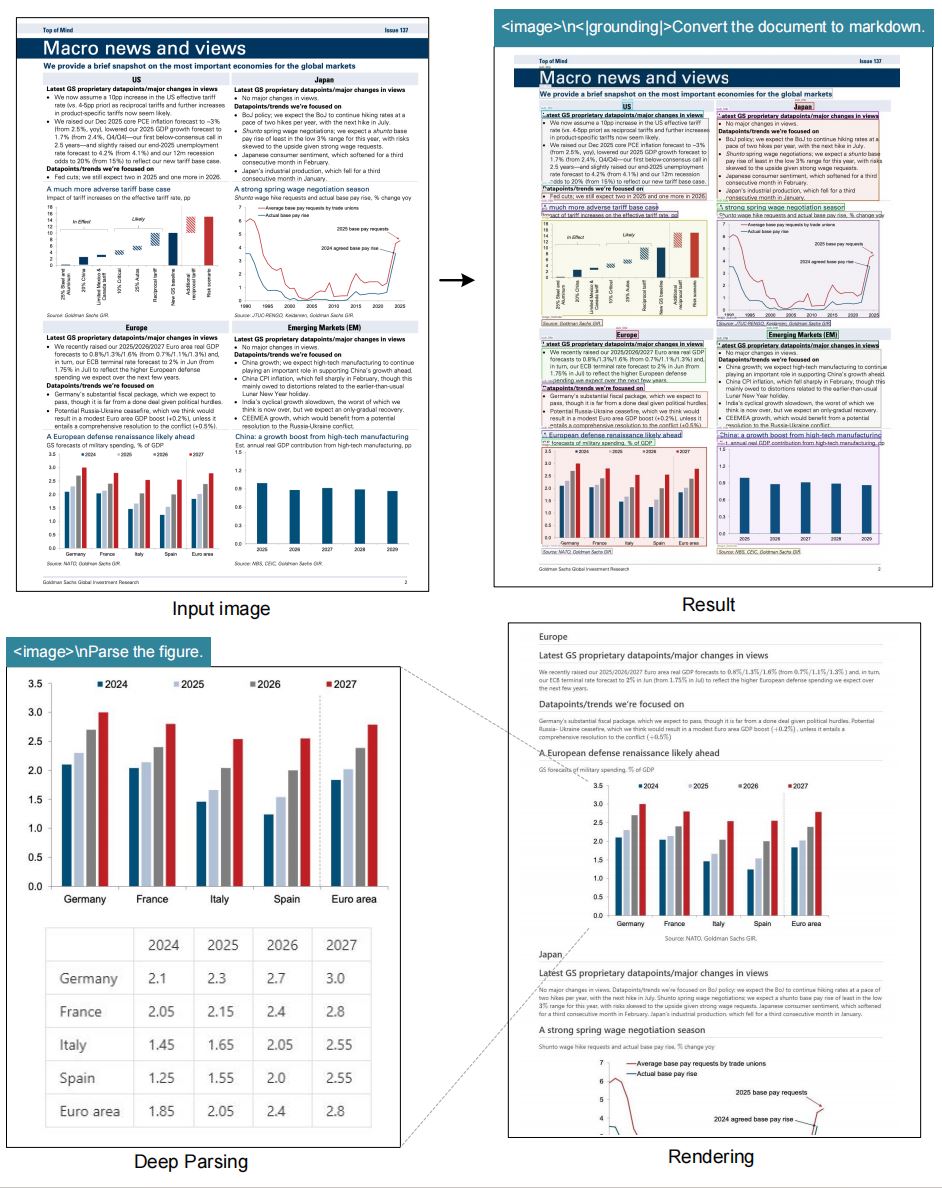
Erstellen Sie Prompts wie "<|grounding|>Convert the document to markdown" oder "Locate <|ref|>invoice total<|/ref|>", um Markdown, HTML, JSON oder gezielte Textspannen mit nur einem deepseek ocr Aufruf zu erhalten.
Die Kompression visueller Token hält den Inferenzdurchsatz hoch — bis zu ~2500 Tokens/s auf A100 40G via vLLM — und bewahrt die deepseekocr Lesbarkeit für lange PDFs.
Unter der MIT-Lizenz veröffentlicht, lädt deepseek-ocr zu Pull Requests, lokalisierter Dokumentation und Community-Finetunes für akademische, Unternehmens- und Behörden-Workloads ein.
Benchmarks auf OmniDocBench zeigen, dass deepseek ocr mehrzeilige Tabellen ausgerichtet hält und den Spaltenversatz klassischer, vorlagenbasierter OCR-Dienste vermeidet.
Läuft mit vLLM, Transformers oder benutzerdefinierten Pipelines in CUDA-11.8+-Umgebungen. Tutorials decken lokale Workstations, verwaltetes Kubernetes und serverlose GPU-Bursts ab.
Kombinieren Sie deepseek ocr mit Retrieval-augmented Generation, Dokumentenagenten oder nachgelagerter Analytik, um manuelle Prüfung zu minimieren. Die deepseekocr Roadmap wächst weiter — achten Sie auf neue deepseek-ocr Checkpoints, die Latenz senken und die Genauigkeit bei niedrig aufgelösten Scans erhöhen.
Kennzahlen von GitHub, Hugging Face und Community-Labortests bestätigen die Zuverlässigkeit von deepseekocr für globale Workloads.
Deepseek ocr komprimiert visuelle Token bei 10× mit kaum Verlusten. Selbst bei 20× bleiben 60 % Genauigkeit erhalten — ideal für kostensensitive Ingestion-Pipelines.
Hugging Face meldet 22,9 M monatliche Besuche für deepseek-ocr Assets, während GitHub 471,49 M eindeutige Interaktionen verzeichnet und damit Produktionsreife belegt.
LLM-zentriertes Reasoning erlaubt deepseekocr, Diagramme zu beschreiben, Belege zu annotieren und Bounding Boxes zu beschriften, ohne separate OCR- plus NLP-Stacks.
Führen Sie Datenschutzprüfungen für sensible Einsätze durch — Community-Feedback unterstreicht, wie wichtig es ist, Halluzinationen bei juristischen und medizinischen Unterlagen zu minimieren.
Da deepseek ocr als Vision-Language-Modell arbeitet, sollten Benchmarks Prompt-Engineering und Post-Processing-Metriken berücksichtigen. Überwachen Sie die deepseekocr Präzision zusammen mit manuellen Stichproben, um sicherzustellen, dass deepseek-ocr Rollouts regulatorische Erwartungen erfüllen.
Von Entwickler-Sandboxes bis zu Enterprise-Dokumentenintelligenz passt sich deepseek ocr schnell an.
Verwandeln Sie bildbasierte PDFs in durchsuchbares Markdown, extrahieren Sie Fußnoten und erstellen Sie automatische Zusammenfassungen mit deepseekocr Prompts plus RAG-Toolchains. Deepseek ocr liefert normalisierten Text, Bounding Boxes und visuelle Hinweise, sodass nachgelagerte Suchindizes vertrauenswürdig bleiben.
Kombinieren Sie deepseek-ocr mit n8n oder benutzerdefinierten HTTP-Knoten, um nachgelagerte GPT-, Claude- oder Gemini-Reasoning-Schritte auszulösen und strukturierte Tabellenausgaben zu bewahren. So entsteht eine automatisierte Kette, in der deepseek ocr präzise Extraktion übernimmt und Bots Entscheidungen treffen.
Bereiten Sie die MIT-lizenzierten Gewichte in privaten Rechenzentren auf, damit vertrauliche Verträge, Ausweise oder Laborjournale unter Ihrer Hoheit bleiben. Deepseekocr Checkpoints lassen sich leicht quantisieren und ermöglichen abgeschottete deepseek-ocr Umgebungen, die Auditor:innen überzeugen.
Bildungseinrichtungen archivieren historische Magazine und handschriftliche Notizen, indem sie deepseek ocr mit manueller Prüfung kombinieren und so Transkriptionszyklen drastisch verkürzen. Bibliotheken nutzen deepseekocr Metadaten, um Rechercheportale und Digital-Humanities-Projekte zu befeuern.
Telemetrie von Hugging Face, GitHub und der weiteren Entwicklercommunity zeigt, wie deepseek ocr sich von einer Forschungsfreigabe zum produktiven OCR-Rückgrat entwickelt.
Hugging Face meldet 22,9 M monatliche Sitzungen auf der offiziellen Demo, während GitHub-Projekte mit Bezug zu deepseekocr und deepseek-ocr bereits 471,49 M Aufrufe überschritten haben. Das Interesse an kompressionsbewusstem OCR zeigt, dass Entwickler:innen moderne Tools wollen, die Layout-Kontext bewahren, ohne GPU-Kosten explodieren zu lassen.
Jeder neue Checkpoint führt die Agenda der "kontextuellen optischen Kompression" fort: deepseek ocr erreicht bei 10× Kompression nahezu verlustfreie Genauigkeit und behält bei 20× rund 60 % Validität. Produktteams bearbeiten dadurch größere Backlogs mit weniger Ressourcen und liefern dennoch formatierten Text, dem nachgelagerte Systeme vertrauen.
Hacker-News-Threads analysieren das deepseek-ocr Whitepaper und diskutieren, wie semantisches Token-Pooling gegenüber klassischen OCR-Heuristiken abschneidet. Auf Reddit (r/LocalLLaMA, r/MachineLearning) und in Automatisierungsforen finden Sie Tutorials, die deepseek ocr in n8n, Airflow und maßgeschneiderte ETL-Jobs einbinden.
Operator:innen loben, wie deepseekocr komplexe Tabellen und Handschrift verarbeitet, warnen aber vor blindem Vertrauen — Qualitätskontrollen, JSON-Schema-Validierung und Stichproben bleiben Best Practices. Die Lehre: Kombinieren Sie deepseek-ocr mit schlanken Review-Workflows, um Halluzinationen zu eliminieren, bevor Daten in CRMs oder BI-Systeme fließen.
Analyst:innen vergleichen deepseek ocr mit Azure Document Intelligence, Google Vision API und ABBYY, um abzuschätzen, wann offene Modelle kommerzielle SaaS-Lösungen verdrängen können. Benchmarks von OmniAI und AI Advances zeigen, dass sich der Abstand schnell schließt, da deepseekocr Tabellenabgleich und Robustheit bei schwachem Licht verbessert.
Unternehmensberichte heben deepseek-ocr in Compliance-Archiven, Logistikbelegen und Pharma-Kennzeichnungen hervor. Teams kombinieren vLLM-Microservices, FastAPI und n8n-Templates, sodass deepseek ocr Ausgaben RAG-Suche, Support-Copiloten oder RPA-Bots mit minimalem Glue Code speisen.
Folgen Sie diesen Schritten, um deepseekocr in Ihren Stack einzubetten.
Klonen Sie github.com/deepseek-ai/DeepSeek-OCR, erstellen Sie eine Python-3.12-Umgebung und installieren Sie torch==2.6.0, vllm==0.8.5 und die Projektabhängigkeiten. Optional: ergänzen Sie flash-attn für schnelle Inferenz.
Für abgeschottete Deployments führen Sie pip download aus, um Wheels vorzubereiten, spiegeln die Modellgewichte in Ihrem Artefaktspeicher und automatisieren Sie Checksum-Validierung, damit deepseek-ocr über mehrere Nodes reproduzierbar bleibt.
Nutzen Sie run_dpsk_ocr_image.py für Streaming-Ausgaben bei Bildern oder run_dpsk_ocr_pdf.py für lange PDFs. Transformers-Anwender:innen können model.infer(... test_compress=True) aufrufen, um Kompression zu evaluieren.
In Produktions-Stacks wird deepseek ocr häufig mit vLLM-Microservices oder einem FastAPI-Gateway gekapselt; skalieren Sie GPU-Worker automatisch, erfassen Sie Metriken und stellen Sie Health-Endpoints bereit, damit deepseekocr unter Last berechenbar bleibt.
Verwenden Sie Prompt-Templates wie "<image>\n<|grounding|>Convert the document to markdown." für Layout-Treue oder "Locate <|ref|>tax rate<|/ref|>", um gezielte Werte zu greifen.
Ergänzen Sie Layout-Hinweise ("preserve multi-column format") und Sprachhinweise ("respond in English"), damit deepseekocr konsistente Strukturen liefert. Versionieren Sie bewährte deepseek-ocr Prompts, um Teams zu synchronisieren.
Setzen Sie Qualitätsprüfungen gegen Halluzinationen ein, überwachen Sie Kompressionsraten und arbeiten Sie mit Community-Issue-Trackern, um die deepseek ocr Performance hoch zu halten.
Senden Sie Metriken an Grafana oder Prometheus — verfolgen Sie OCR-Erfolgsraten, durchschnittliche Kompressionsziele und den Anteil menschlicher Prüfungen, damit deepseek-ocr Entscheidungen auditfest bleiben.
Deepseek-ocr baut auf offenen Community-Benchmarks wie GOT-OCR2.0 und MinerU auf und dankt Vary, PaddleOCR, OneChart, Slow Perception, Fox und OmniDocBench für öffentlich verfügbare Evaluierungssuiten.
Teams ergänzen diese Korpora durch öffentliche Scans aus Annas Archive, Gerichtsakten und Unternehmens-PDFs, um Fine-Tunes zu erstellen, die ihre Domäne widerspiegeln. Langschwanz-Beispiele halten deepseek-ocr robust, wenn sich Daten ändern.
Aktivieren Sie test_compress=True, fordern Sie JSON-Schema-Validierung an und gleichen Sie Extraktionen abschließend mit regelbasierten Regex ab. Für kritische Workloads kombinieren Sie deepseek ocr mit menschlicher Prüfung.
Community-Playbooks empfehlen einen zweistufigen Ablauf — führen Sie deepseekocr aus, fassen Sie danach mit einem LLM zusammen und protokollieren Sie Konfidenzwerte plus Differenzvisualisierungen. Alles unterhalb des Schwellenwerts geht an Menschen statt direkt in Produktivsysteme.
Ja. Die Varianten Tiny und Small laufen bequem auf 12 GB VRAM, während Base und Gundam von 24 GB+ profitieren. Community-Guides für Linux, Windows und macOS decken die Installation ab.
Für Edge-Geräte quantisieren Sie den Tiny-Checkpoint und exportieren ihn über TensorRT-LLM oder ONNX Runtime, um deepseek ocr unter engen Strombudgets auf Kiosken, Industriescannern oder Robotik bereitzustellen.
Öffnen Sie Pull Requests im offiziellen GitHub-Repository oder teilen Sie lokalisierte Prompts in den Hugging-Face-Diskussionen. deepseekocr priorisiert zweisprachige (Englisch & Vereinfachtes Chinesisch) Dokumentations-Updates.
Teilen Sie Skripte, Dockerfiles und Workflow-Guides über GitHub, Hugging Face oder Reddit, damit die umfassendere deepseek-ocr Community Erfolge reproduzieren und Deployment-Zeitpläne beschleunigen kann.