Modo Gundam de resolución dinámica
Deepseek-ocr Gundam combina inteligentemente recortes de 640×640 y 1024×1024 para que facturas densas, esquemas y revistas multicolumna sigan legibles sin inflar la ventana de contexto.
Deepseek ocr comprime la evidencia visual en tokens densos para que los equipos puedan reconstruir texto, diseño y semántica en una sola pasada. La publicación de código abierto combina OCR, grounding y razonamiento, lo que permite transmitir Markdown, JSON o prosa ricamente anotada a partir de facturas, registros de fabricación y revistas multilingües sin comprometer la privacidad de los datos.
Los equipos despliegan deepseekocr con vLLM, Transformers y runtimes de borde para automatizar auditorías de cumplimiento, ingerir bases de conocimiento y activar automatización robótica de procesos. Con deepseek-ocr puede orquestar canalizaciones de inteligencia documental explicables, escalables y adaptadas a más de 90 idiomas.
Las analíticas de Hugging Face confirman que deepseek ocr es el espacio predeterminado para ingenieros que validan la extracción multimodal antes de entrar en producción.
Los repositorios que catalogan técnicas de deepseekocr y deepseek-ocr acumulan cientos de millones de vistas, lo que evidencia un ecosistema de integración en rápida maduración.
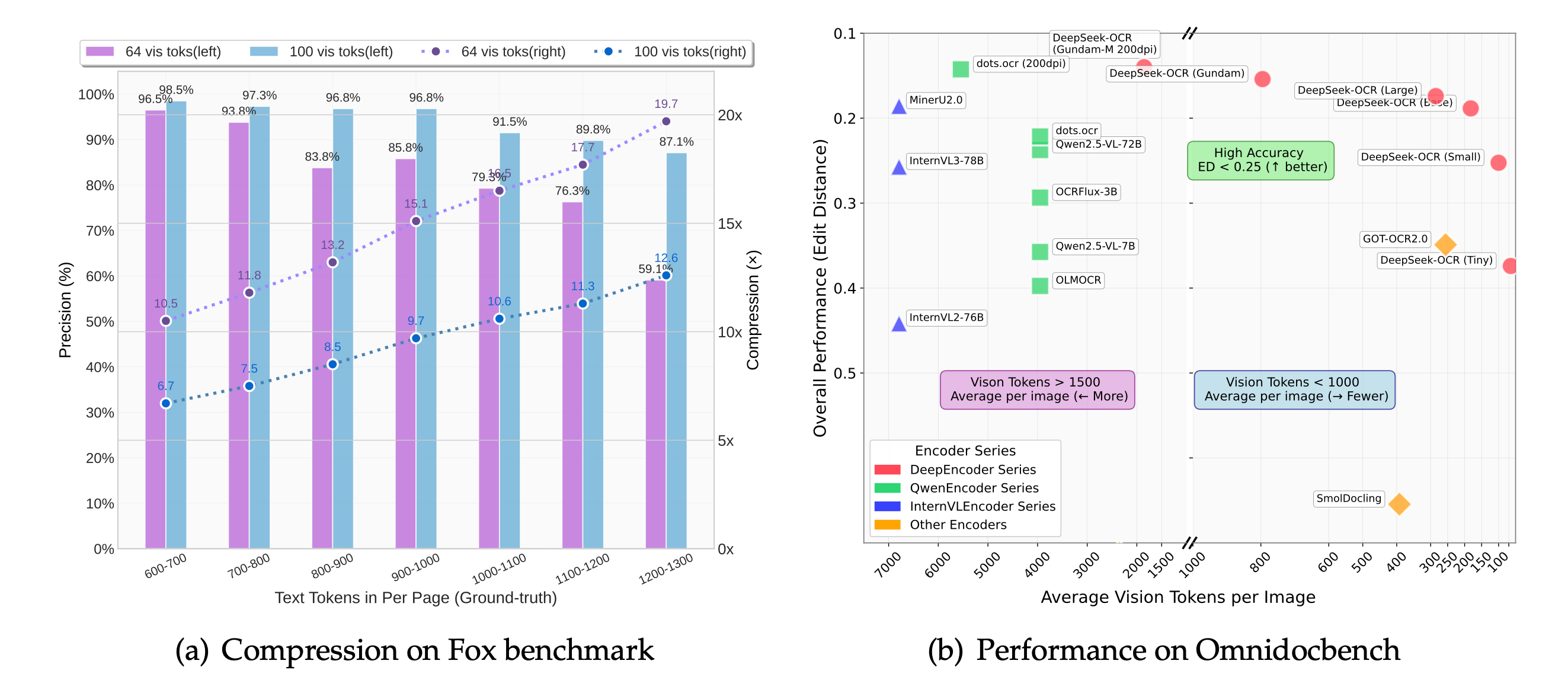
La compresión de tokens visuales mantiene a deepseek-ocr casi sin pérdidas mientras reduce el costo de GPU, permitiéndole escalar colas de documentos sin sacrificar fidelidad.
Los pipelines de resolución dinámica permiten que deepseek ocr descodifique maquetas latinas, CJK y RTL para pasaportes, prospectos farmacéuticos y archivos de cumplimiento.
Experimente con el espacio de Hugging Face de DeepSeek-OCR para analizar recibos, PDFs densos, tablas y activos multilingües. El laboratorio incrustado replica el playground oficial de deepseek ocr para que pruebe prompts de deepseekocr sin salir de deepseekocr.org.
Cargue facturas de ejemplo, suba escaneos de contratos o pegue capturas para comparar la salida de deepseek-ocr con motores OCR tradicionales. Para una mejor experiencia, abra la demo en pantalla completa y ajuste el control de compresión para observar cómo deepseek ocr equilibra calidad y velocidad.
Vea cómo deepseek ocr y su variante deepseek-ocr Gundam mantienen alineadas y legibles las facturas comerciales, los folletos multilingües, los diagramas científicos y los recibos de comercio electrónico incluso bajo compresión agresiva.



La pila deepseek ocr fusiona tokens de visión dinámicos con razonamiento LLM, ofreciendo una precisión que los motores clásicos no logran igualar.
Deepseek-ocr Gundam combina inteligentemente recortes de 640×640 y 1024×1024 para que facturas densas, esquemas y revistas multicolumna sigan legibles sin inflar la ventana de contexto.
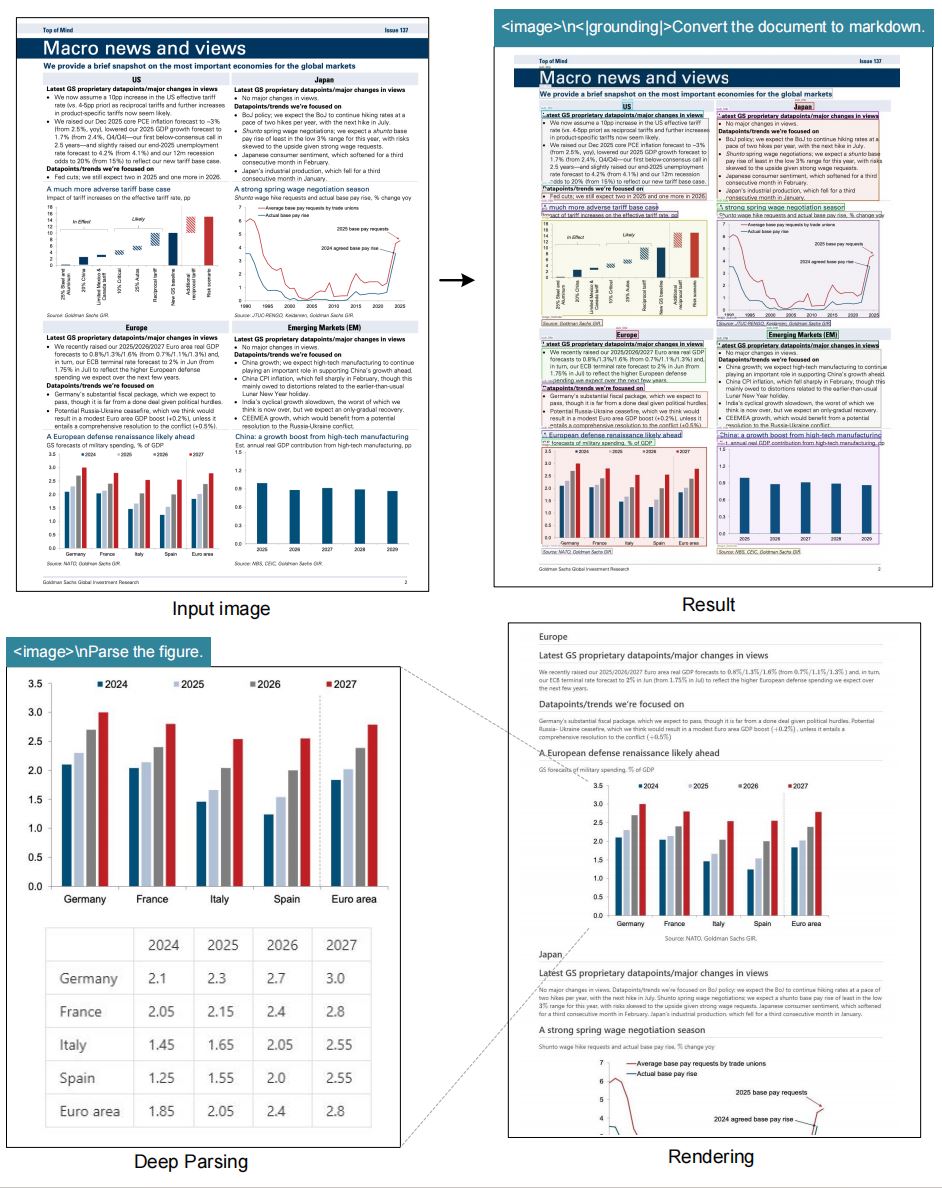
Construya prompts como "<|grounding|>Convert the document to markdown" o "Locate <|ref|>invoice total<|/ref|>" para obtener Markdown, HTML, JSON o segmentos dirigidos en una sola llamada a deepseek ocr.
La compresión de tokens visuales mantiene un throughput alto — hasta ~2500 tokens/s en A100 40G con vLLM — mientras preserva la legibilidad de deepseekocr en PDFs de largo contexto.
Bajo licencia MIT, deepseek-ocr invita a pull requests, documentación localizada y fine-tunes comunitarios para cargas académicas, empresariales y gubernamentales.
Las ejecuciones en OmniDocBench muestran que deepseek ocr mantiene alineadas las tablas con múltiples encabezados, mitigando el desplazamiento de columnas que afecta a los servicios OCR basados en plantillas.
Funciona con vLLM, Transformers o pipelines personalizados en entornos CUDA 11.8+. Los tutoriales cubren estaciones locales, Kubernetes gestionado y ráfagas de GPU serverless.
Combine deepseek ocr con retrieval-augmented generation, agentes de comprensión documental o analítica posterior para minimizar la revisión manual. La hoja de ruta de deepseekocr sigue creciendo — esté atento a nuevos checkpoints de deepseek-ocr que reduzcan la latencia y aumenten la precisión en escaneos de baja resolución.
Datos de GitHub, Hugging Face y laboratorios de la comunidad refuerzan la fiabilidad de deepseekocr en cargas globales.
Deepseek ocr comprime tokens visuales a 10× con pérdida mínima. Incluso a 20× mantiene 60 % de precisión, ideal para pipelines de ingestión sensibles al costo.
Hugging Face reporta 22,9 M de visitas mensuales a los activos de deepseek-ocr, mientras que GitHub registra 471,49 M de interacciones únicas, subrayando su preparación para producción.
El razonamiento centrado en LLM permite que deepseekocr narre diagramas, anote recibos y etiquete bounding boxes sin necesidad de pilas OCR + NLP separadas.
Implemente revisiones de privacidad en despliegues sensibles — los comentarios de la comunidad resaltan la importancia de minimizar alucinaciones en registros legales y sanitarios.
Como deepseek ocr opera como un modelo visión-lenguaje, las comparativas deben incluir métricas de prompt engineering y posprocesamiento. Supervise la precisión de deepseekocr junto a muestreos manuales para garantizar que los despliegues de deepseek-ocr cumplan las exigencias regulatorias.
Desde sandboxing para desarrolladores hasta inteligencia documental empresarial, deepseek ocr se adapta con rapidez.
Transforme PDFs basados en imagen en Markdown searchable, extraiga notas al pie y genere resúmenes automáticos con prompts de deepseekocr y toolchains RAG. Deepseek ocr entrega texto normalizado, bounding boxes y pistas visuales para que los índices de búsqueda posteriores sigan siendo fiables.
Combine deepseek-ocr con n8n o nodos HTTP personalizados para activar pasos de razonamiento con GPT, Claude o Gemini y preservar salidas tabulares estructuradas. El resultado es una cadena automatizada donde deepseek ocr gestiona la extracción precisa y los bots toman decisiones.
Implemente los pesos con licencia MIT en centros de datos privados para mantener contratos confidenciales, identificaciones o cuadernos de laboratorio bajo su gobernanza. Los checkpoints de deepseekocr se cuantizan con facilidad y permiten entornos deepseek-ocr aislados que satisfacen a los auditores.
Educadores archivan revistas históricas y notas manuscritas combinando deepseek ocr con revisión manual, reduciendo drásticamente los ciclos de transcripción. Bibliotecarios aprovechan los metadatos de deepseekocr para impulsar portales de descubrimiento y proyectos de humanidades digitales.
La telemetría de Hugging Face, GitHub y la comunidad de desarrolladores muestra cómo deepseek ocr evoluciona de un lanzamiento de investigación a columna vertebral OCR en producción.
Hugging Face reporta 22,9 M de sesiones mensuales en la demo oficial, mientras que los proyectos de GitHub que referencian deepseekocr y deepseek-ocr superan 471,49 M vistas. El apetito por OCR consciente de la compresión evidencia que los desarrolladores quieren herramientas modernas que preserven el contexto de diseño sin disparar los costos de GPU.
Cada nuevo checkpoint continúa la agenda de "compresión óptica contextual": deepseek ocr alcanza precisión casi sin pérdidas con compresión de 10× y mantiene cerca del 60 % de fidelidad a 20×. Así los equipos de producto procesan backlog mayores con menos recursos y entregan texto formateado en el que los sistemas posteriores pueden confiar.
Hilos en Hacker News analizan el whitepaper de deepseek-ocr y debaten cómo el pooling semántico de tokens se compara con las heurísticas OCR tradicionales. En Reddit (r/LocalLLaMA, r/MachineLearning) y foros de automatización encontrará tutoriales que conectan deepseek ocr con n8n, Airflow y trabajos ETL personalizados.
Operadores elogian la forma en que deepseekocr maneja tablas complejas y escritura manual, pero advierten contra la confianza ciega — controles de calidad, validación de esquemas JSON y auditorías puntuales siguen siendo la mejor práctica. La lección compartida: combine deepseek-ocr con flujos de revisión ligeros para eliminar alucinaciones antes de que los datos lleguen a CRMs o sistemas BI.
Analistas comparan deepseek ocr con Azure Document Intelligence, Google Vision API y ABBYY para evaluar cuándo los modelos abiertos pueden sustituir SaaS comerciales. Benchmarks de OmniAI y AI Advances muestran que la brecha se cierra rápidamente a medida que deepseekocr mejora la alineación de tablas y la robustez con poca luz.
Casos de estudio empresariales destacan deepseek-ocr en archivos de cumplimiento, recibos logísticos y etiquetado farmacéutico. Los equipos combinan microservicios vLLM, FastAPI y plantillas de n8n para alimentar búsquedas RAG, copilotos de soporte o bots de automatización con salidas de deepseek ocr sin apenas glue code.
Siga estos pasos para integrar deepseekocr en su stack.
Clone github.com/deepseek-ai/DeepSeek-OCR, cree un entorno de Python 3.12 e instale torch==2.6.0, vllm==0.8.5 y los requisitos del proyecto. Opcional: agregue flash-attn para acelerar la inferencia.
Para despliegues aislados ejecute pip download y prepare los wheels, replique los pesos del modelo en su repositorio de artefactos y automatice la validación de checksums para que deepseek-ocr sea reproducible entre nodos.
Use run_dpsk_ocr_image.py para salidas en streaming de imágenes o run_dpsk_ocr_pdf.py para PDFs extensos. Quienes emplean Transformers pueden llamar a model.infer(... test_compress=True) para evaluar la compresión.
Los stacks de producción suelen envolver deepseek ocr con microservicios vLLM o una pasarela FastAPI; escale workers de GPU, capture métricas y exponga endpoints de salud para mantener deepseekocr predecible bajo carga.
Adopte plantillas como "<image>\n<|grounding|>Convert the document to markdown." para conservar el diseño o "Locate <|ref|>tax rate<|/ref|>" para capturar valores concretos.
Añada indicaciones de diseño ("preserve multi-column format") y de idioma ("respond in English") para que deepseekocr devuelva estructuras consistentes. Versione los prompts probados de deepseek-ocr para alinear a los equipos.
Implemente controles de calidad contra alucinaciones, monitorice las tasas de compresión y colabore con los issue trackers de la comunidad para mantener alto el rendimiento de deepseek ocr.
Envie métricas a Grafana o Prometheus — siga tasas de éxito de OCR, objetivos de compresión promedio y porcentajes de revisión humana para que las decisiones de deepseek-ocr resistan auditorías.
Deepseek-ocr se apoya en benchmarks abiertos de la comunidad como GOT-OCR2.0 y MinerU, con agradecimientos a Vary, PaddleOCR, OneChart, Slow Perception, Fox y OmniDocBench por sus suites de evaluación públicas.
Los equipos amplían estos corpus con escaneos públicos de Anna's Archive, expedientes legales y PDFs empresariales para crear fine-tunes alineados con su dominio. Alimentar al modelo con muestras de cola larga mantiene a deepseek-ocr robusto frente al drift de datos.
Active test_compress=True, solicite validación de esquemas JSON y contraste las extracciones con expresiones regulares como guardarraíl final. Para cargas críticas combine deepseek ocr con revisión humana.
Los playbooks comunitarios recomiendan un flujo en dos etapas — ejecute deepseekocr, luego resuma con un LLM registrando puntajes de confianza y visualizaciones de diferencias. Todo lo que quede por debajo del umbral se dirige a personas antes de entrar en producción.
Sí. Las variantes Tiny y Small funcionan cómodamente en tarjetas de 12 GB de VRAM, mientras que Base y Gundam se benefician de 24 GB o más. Guías comunitarias para Linux, Windows y macOS cubren la instalación.
Para dispositivos perimetrales, cuantice el checkpoint Tiny y expórtelo con TensorRT-LLM u ONNX Runtime para mantener deepseek ocr dentro de presupuestos energéticos estrictos en quioscos, escáneres industriales o robótica.
Abra pull requests en el repositorio oficial de GitHub o comparta prompts localizados en los debates de Hugging Face. deepseekocr prioriza actualizaciones de documentación bilingüe (inglés y chino simplificado).
Comparta scripts, Dockerfiles y guías de flujo mediante GitHub, Hugging Face o Reddit para que la comunidad amplia de deepseek-ocr replique éxitos y acelere los cronogramas de despliegue.