Mode Gundam à résolution dynamique
Deepseek-ocr Gundam combine intelligemment des recadrages 640×640 et 1024×1024 afin que factures denses, schémas et magazines multicolonnes restent lisibles sans dilater la fenêtre de contexte.
Deepseek ocr compresse les preuves visuelles en tokens denses, permettant aux équipes de reconstruire texte, mise en page et sémantique en un passage. La publication open source fusionne OCR, grounding et raisonnement pour diffuser du Markdown, du JSON ou une prose richement annotée issue de factures, journaux industriels et magazines multilingues sans compromettre la confidentialité des données.
Les équipes déploient deepseekocr avec vLLM, Transformers et des runtimes edge pour automatiser les audits de conformité, ingérer des bases de connaissances et déclencher la robotisation des processus. Avec deepseek-ocr vous orchestrez des pipelines d'intelligence documentaire explicables, évolutifs et adaptés à plus de 90 langues.
Les analyses Hugging Face confirment que deepseek ocr est le terrain d'essai privilégié des ingénieurs qui valident l'extraction multimodale avant la production.
Les dépôts cataloguant les techniques deepseekocr et deepseek-ocr cumulent des centaines de millions de vues, signe d'un écosystème d'intégration en pleine maturité.
La compression des tokens visuels maintient deepseek-ocr quasi sans perte tout en réduisant les coûts GPU, ce qui permet de faire évoluer les files de documents sans sacrifier la fidélité.
Des pipelines à résolution dynamique permettent à deepseek ocr de décoder des mises en page latines, CJK et RTL pour les passeports, notices pharmaceutiques et archives de conformité.
Expérimentez l'espace Hugging Face DeepSeek-OCR pour analyser reçus, PDFs denses, tableaux et ressources multilingues. Le laboratoire embarqué reflète le playground officiel deepseek ocr afin de tester vos prompts deepseekocr sans quitter deepseekocr.org.
Chargez des factures d'exemple, importez des scans de contrats ou collez des captures d'écran pour comparer la sortie deepseek-ocr aux moteurs OCR historiques. Pour une expérience optimale, ouvrez la démo en plein écran et ajustez le curseur de compression pour observer comment deepseek ocr équilibre qualité et vitesse.
Découvrez comment deepseek ocr et sa variante deepseek-ocr Gundam maintiennent factures commerciales, brochures multilingues, schémas scientifiques et reçus e-commerce alignés et lisibles, même sous forte compression.



La pile deepseek ocr fusionne tokens visuels dynamiques et raisonnement LLM pour un niveau de précision que les moteurs classiques peinent à atteindre.
Deepseek-ocr Gundam combine intelligemment des recadrages 640×640 et 1024×1024 afin que factures denses, schémas et magazines multicolonnes restent lisibles sans dilater la fenêtre de contexte.
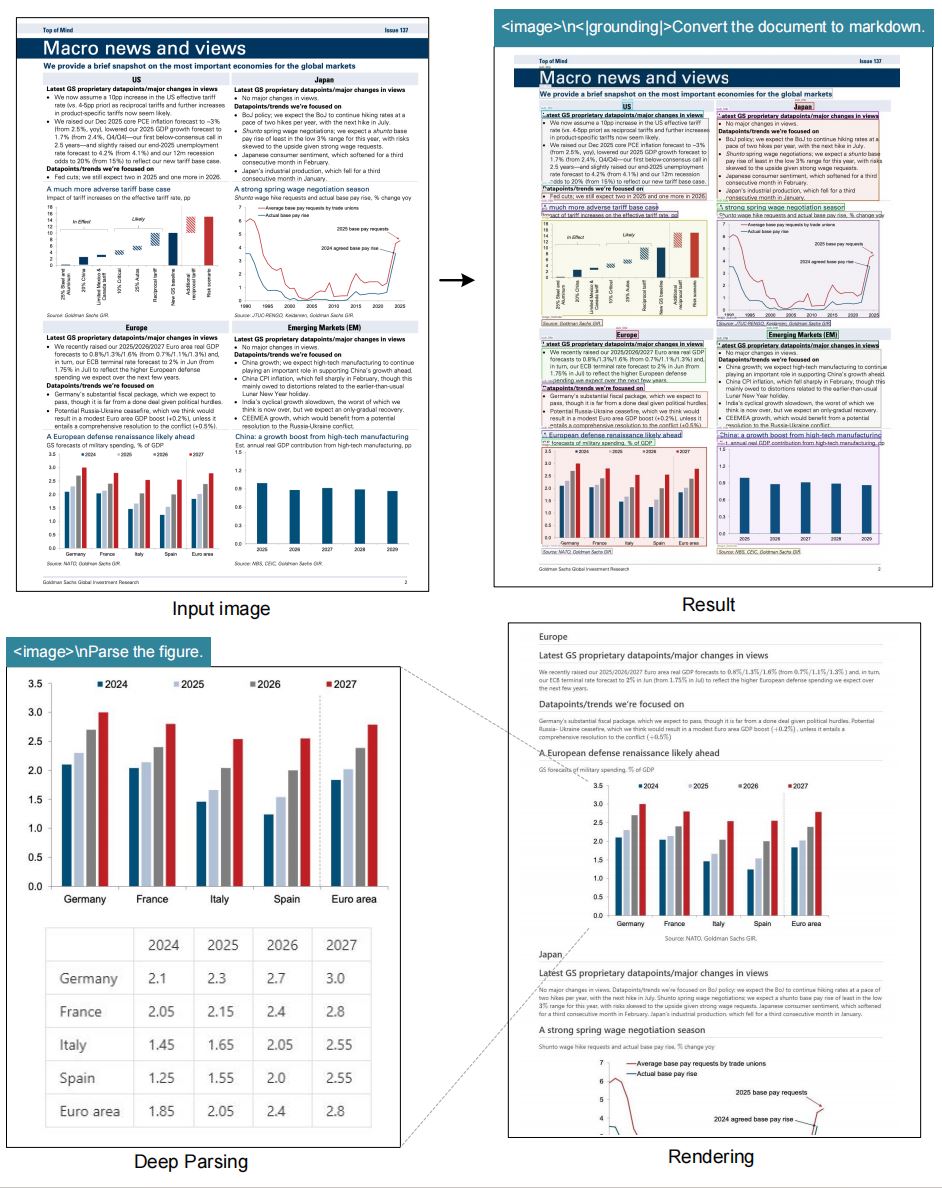
Créez des prompts comme "<|grounding|>Convert the document to markdown" ou "Locate <|ref|>invoice total<|/ref|>" pour obtenir Markdown, HTML, JSON ou segments ciblés en un seul appel deepseek ocr.
La compression des tokens visuels maintient un débit d'inférence élevé — jusqu'à ~2500 tokens/s sur A100 40G via vLLM — tout en préservant la lisibilité deepseekocr pour les PDFs longs.
Sous licence MIT, deepseek-ocr encourage pull requests, documentation localisée et fine-tunes communautaires pour les charges académiques, entreprises et administrations.
Les benchmarks OmniDocBench montrent que deepseek ocr maintient l'alignement des tableaux multi-entêtes, réduisant la dérive de colonnes qui touche les services OCR basés sur des modèles.
Fonctionne avec vLLM, Transformers ou des pipelines personnalisés sur des environnements CUDA 11.8+. Des tutoriels couvrent stations locales, Kubernetes managé et pics GPU serverless.
Combinez deepseek ocr avec la génération augmentée par recherche, des agents de compréhension documentaire ou l'analytique descendante pour minimiser la vérification manuelle. La feuille de route deepseekocr continue de s'élargir — surveillez les nouveaux checkpoints deepseek-ocr qui réduisent la latence tout en améliorant la précision sur les scans basse résolution.
Des données issues de GitHub, Hugging Face et des labs communautaires confirment la fiabilité de deepseekocr sur des charges mondiales.
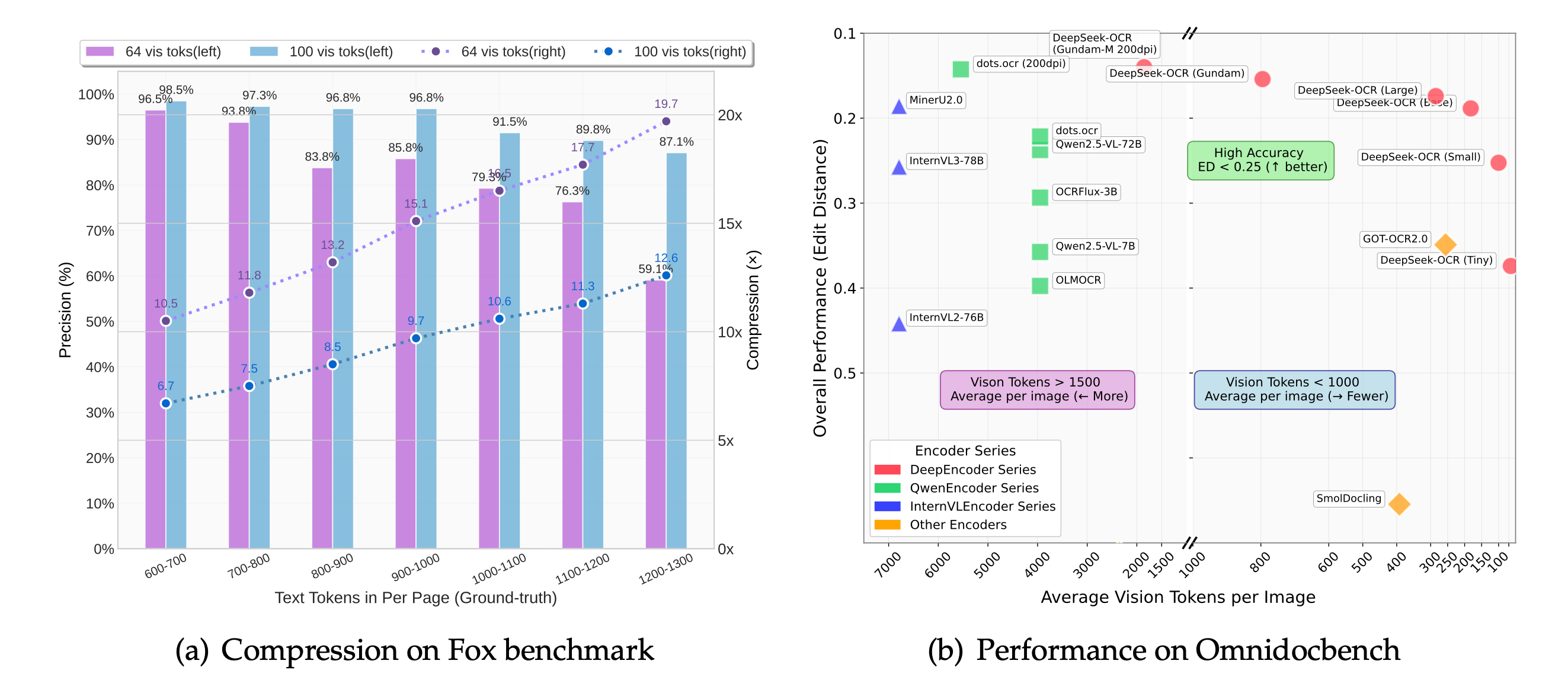
Deepseek ocr comprime les tokens visuels à 10× avec une perte négligeable. Même à 20×, 60 % de précision subsistent — parfait pour les pipelines d'ingestion sensibles aux coûts.
Hugging Face recense 22,9 M de visites mensuelles pour les ressources deepseek-ocr, tandis que GitHub comptabilise 471,49 M d'interactions uniques, gage de maturité industrielle.
Le raisonnement centré LLM permet à deepseekocr de raconter des schémas, annoter des reçus et étiqueter des bounding boxes sans empiler OCR et NLP séparés.
Menez des revues de confidentialité pour les déploiements sensibles — les retours communautaires soulignent l'importance de réduire les hallucinations pour les dossiers juridiques et médicaux.
Puisque deepseek ocr fonctionne comme un modèle vision-langage, l'interprétation des benchmarks doit intégrer prompt engineering et métriques de post-traitement. Surveillez la précision deepseekocr en parallèle d'échantillons manuels pour garantir que les déploiements deepseek-ocr respectent les attentes réglementaires.
Du bac à sable développeur à l'intelligence documentaire d'entreprise, deepseek ocr s'adapte rapidement.
Convertissez des PDFs image en Markdown interrogeable, extrayez des notes de bas de page et générez des résumés automatiques avec les prompts deepseekocr et des chaînes RAG. Deepseek ocr fournit texte normalisé, bounding boxes et indices visuels pour fiabiliser les index de recherche aval.
Associez deepseek-ocr à n8n ou des nœuds HTTP sur mesure pour déclencher des étapes de raisonnement GPT, Claude ou Gemini tout en conservant des tableaux structurés. Résultat : une chaîne automatisée où deepseek ocr assure l'extraction précise et où les bots pilotent les décisions.
Déployez les poids sous licence MIT dans des data centers privés afin que contrats, pièces d'identité ou cahiers de labo restent sous votre gouvernance. Les checkpoints deepseekocr se quantifient aisément et autorisent des environnements deepseek-ocr isolés conformes aux audits.
Les éducateurs archivent magazines anciens et notes manuscrites en combinant deepseek ocr et relecture manuelle, réduisant radicalement les cycles de transcription. Les bibliothécaires appuient leur portail de découverte et les projets de sciences humaines numériques sur les métadonnées deepseekocr.
La télémétrie Hugging Face, GitHub et de la communauté développeurs illustre la transformation de deepseek ocr, passé d'un projet de recherche à une colonne vertébrale OCR en production.
Hugging Face dénombre 22,9 M de sessions mensuelles sur la démo officielle, tandis que les projets GitHub citant deepseekocr et deepseek-ocr franchissent 471,49 M vues. L'appétit pour un OCR conscient de la compression prouve que les développeurs recherchent des outils modernes conservant le contexte de mise en page sans explosion des coûts GPU.
Chaque nouveau checkpoint poursuit l'agenda de "compression optique contextuelle" : deepseek ocr atteint une précision quasi sans perte à 10× et conserve environ 60 % de fidélité à 20×. Les équipes produit traitent ainsi davantage de backlog avec moins de ressources tout en renvoyant un texte structuré fiable pour les systèmes aval.
Des fils Hacker News décortiquent le whitepaper deepseek-ocr et comparent le pooling sémantique de tokens aux heuristiques OCR classiques. Sur Reddit (r/LocalLLaMA, r/MachineLearning) et les forums d'automatisation, on trouve des tutoriels reliant deepseek ocr à n8n, Airflow et des ETL sur mesure.
Les opérateurs saluent la gestion des tableaux complexes et de l'écriture manuscrite par deepseekocr, mais mettent en garde contre la confiance aveugle — garde-fous qualité, validation de schéma JSON et audits ponctuels restent indispensables. La leçon : associez deepseek-ocr à des workflows de revue légers pour éliminer les hallucinations avant d'alimenter CRM ou BI.
Les analystes comparent deepseek ocr à Azure Document Intelligence, Google Vision API et ABBYY afin d'estimer quand les modèles ouverts peuvent remplacer le SaaS commercial. Les benchmarks OmniAI et AI Advances montrent un rattrapage rapide à mesure que deepseekocr améliore l'alignement des tableaux et la robustesse en faible luminosité.
Des cas clients mettent en avant deepseek-ocr dans les archives de conformité, les reçus logistiques et l'étiquetage pharmaceutique. Les équipes mixent microservices vLLM, FastAPI et modèles n8n pour que les sorties deepseek ocr alimentent recherche RAG, copilotes support ou bots RPA avec un minimum de glue code.
Suivez ces étapes pour intégrer deepseekocr à votre stack.
Clonez github.com/deepseek-ai/DeepSeek-OCR, créez un environnement Python 3.12 et installez torch==2.6.0, vllm==0.8.5 ainsi que les dépendances du projet. Optionnel : ajoutez flash-attn pour accélérer l'inférence.
Pour des déploiements isolés, exécutez pip download afin de préparer les wheels, répliquez les poids du modèle dans votre registre d'artefacts et automatisez la vérification des checksums pour garantir la reproductibilité de deepseek-ocr entre les nœuds.
Utilisez run_dpsk_ocr_image.py pour un flux d'images ou run_dpsk_ocr_pdf.py pour des PDFs longs. Les utilisateurs Transformers peuvent appeler model.infer(... test_compress=True) afin d'évaluer la compression.
En production, deepseek ocr est souvent encapsulé dans des microservices vLLM ou une passerelle FastAPI ; auto-scalez les workers GPU, capturez les métriques et exposez des endpoints de santé pour garder deepseekocr prévisible sous charge.
Adoptez des templates tels que "<image>\n<|grounding|>Convert the document to markdown." pour préserver la mise en page ou "Locate <|ref|>tax rate<|/ref|>" pour viser une valeur.
Ajoutez des indices de mise en page ("preserve multi-column format") et de langue ("respond in English") afin que deepseekocr renvoie des structures cohérentes. Versionnez vos prompts deepseek-ocr validés pour aligner les équipes.
Mettez en place des contrôles qualité contre les hallucinations, suivez les ratios de compression et collaborez avec les issue trackers communautaires pour maintenir la performance de deepseek ocr.
Publiez des métriques vers Grafana ou Prometheus — suivez taux de succès OCR, objectifs moyens de compression et part de revue humaine pour que les décisions deepseek-ocr résistent aux audits.
Deepseek-ocr s'appuie sur des benchmarks ouverts tels que GOT-OCR2.0 et MinerU, avec des remerciements à Vary, PaddleOCR, OneChart, Slow Perception, Fox et OmniDocBench pour leurs suites d'évaluation publiques.
Les équipes enrichissent ces corpus par des scans publics d'Anna's Archive, de dossiers juridiques et de PDFs d'entreprise afin de créer des fine-tunes correspondant à leur domaine. Fournir au modèle des échantillons longue traîne garde deepseek-ocr robuste face aux dérives de données.
Activez test_compress=True, demandez une validation de schéma JSON et recoupez les extractions avec des regex comme garde-fou final. Pour les charges critiques, associez deepseek ocr à une revue humaine.
Les playbooks communautaires recommandent un flux en deux étapes — exécuter deepseekocr puis résumer via un LLM tout en journalisant scores de confiance et visualisations de différences. Tout résultat sous seuil est redirigé vers des humains avant usage en production.
Oui. Les variantes Tiny et Small tournent confortablement sur 12 GB de VRAM, tandis que Base et Gundam bénéficient de 24 GB et plus. Des guides communautaires pour Linux, Windows et macOS couvrent l'installation.
Pour les appareils edge, quantifiez le checkpoint Tiny et exportez-le via TensorRT-LLM ou ONNX Runtime afin de garder deepseek ocr dans des budgets énergétiques stricts pour kiosques, scanners industriels ou robotique.
Soumettez des pull requests sur le dépôt GitHub officiel ou partagez des prompts localisés via les discussions Hugging Face. deepseekocr priorise les mises à jour bilingues (anglais et chinois simplifié) de la documentation.
Partagez scripts, Dockerfiles et guides de workflow via GitHub, Hugging Face ou Reddit pour permettre à la communauté deepseek-ocr d'accélérer la reproduction des réussites et les calendriers de déploiement.