動的解像度Gundamモード
deepseek-ocr Gundamは640×640と1024×1024のクロップを賢く切り替え、密な請求書や設計図、マルチカラム雑誌でもコンテキスト長を膨らませずに判読性を保ちます。
Deepseek ocrは視覚的な証拠を高密度トークンに圧縮し、チームがテキスト・レイアウト・セマンティクスを1回の推論で復元できるようにします。オープンソース版はOCR、グラウンディング、推論を統合し、請求書や製造ログ、多言語雑誌からMarkdownやJSON、注釈付きテキストをデータプライバシーを保ったままストリーミングできます。
チームはdeepseekocrをvLLMやTransformers、エッジランタイムと組み合わせ、コンプライアンス監査の自動化、ナレッジベースの取り込み、RPAのトリガーを実現しています。deepseek-ocrを使えば、説明可能でスケーラブル、90言語以上に最適化されたドキュメントインテリジェンスパイプラインを構築できます。
Hugging Faceの分析によると、deepseek ocrは本番導入前にマルチモーダル抽出を検証するエンジニアの標準プレイグラウンドです。
deepseekocrやdeepseek-ocrの手法をまとめたリポジトリは数億規模の閲覧を集め、統合エコシステムの成熟を示しています。
視覚トークンの圧縮により、deepseek-ocrはロスレス品質を保ちながらGPUコストを抑え、忠実度を損なわずに文書キューを拡張できます。
動的解像度パイプラインにより、deepseek ocrはラテン、CJK、RTLレイアウトを解読し、パスポートや医薬品添付文書、コンプライアンスアーカイブに対応します。
DeepSeek-OCRのHugging Face Spaceでレシートや高密度PDF、テーブル、多言語資料を解析しましょう。埋め込みラボは公式のdeepseek ocrプレイグラウンドを再現しており、サイト内でプロンプトを試せます。
サンプル請求書を読み込み、契約書をアップロード、スクリーンショットを貼り付けてdeepseek-ocrと従来OCRの結果を比較しましょう。フルスクリーン表示にして圧縮スライダーを調整すると、deepseek ocrが品質と速度をどう両立するかが分かります。
deepseek ocrとdeepseek-ocr Gundamバリアントが、商用請求書や多言語パンフレット、科学図版、ECレシートを強い圧縮下でも整合性のある状態で保持する様子をご覧ください。



deepseek ocrスタックは動的ビジョントークンとLLM推論を融合し、従来エンジンが追随しにくい精度を実現します。
deepseek-ocr Gundamは640×640と1024×1024のクロップを賢く切り替え、密な請求書や設計図、マルチカラム雑誌でもコンテキスト長を膨らませずに判読性を保ちます。
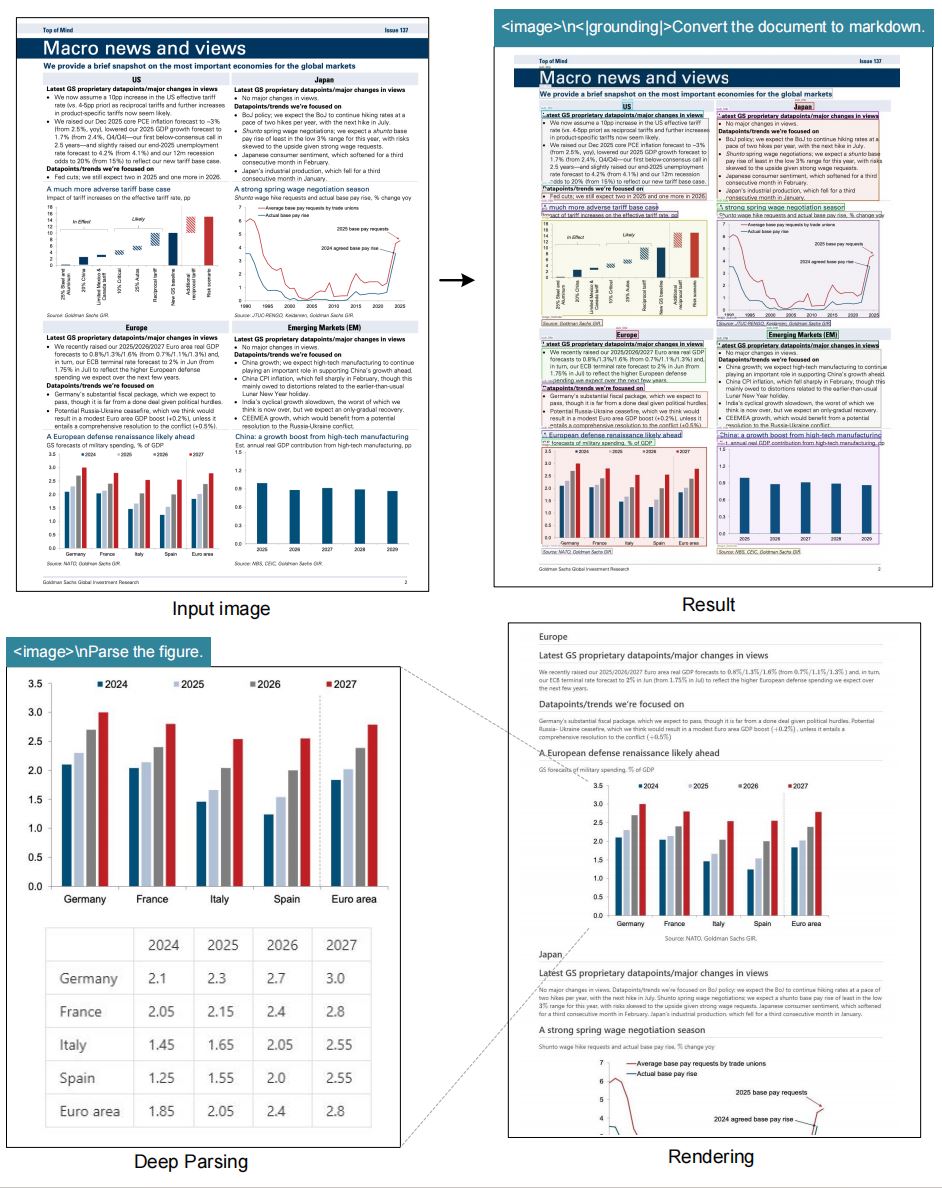
"<|grounding|>Convert the document to markdown"や"Locate <|ref|>invoice total<|/ref|>"といったプロンプトを組み立て、1回のdeepseek ocr呼び出しでMarkdownやHTML、JSON、指定スパンを取得できます。
視覚トークン圧縮により推論スループットを維持しつつ(A100 40GのvLLMで約2500トークン/秒)、長尺PDFでもdeepseekocrの可読性を保ちます。
MITライセンスで公開されたdeepseek-ocrは、アカデミア・企業・公共分野のワークロードに向けたPull Requestやローカライズ文書、コミュニティファインチューニングを歓迎します。
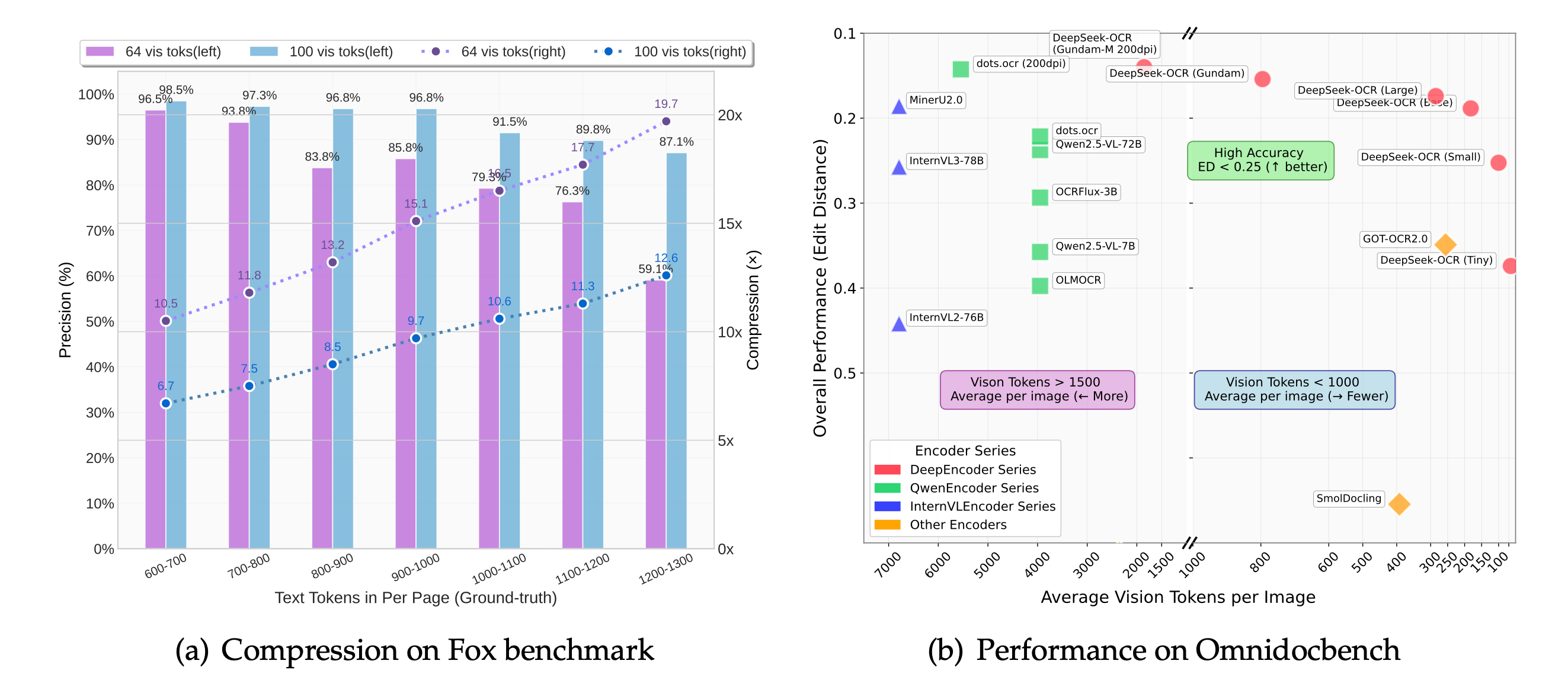
OmniDocBenchのベンチマークでは、deepseek ocrが複数ヘッダーのテーブルを整列させ、テンプレート型OCRで起きがちな列のズレを抑えることが示されています。
vLLMやTransformers、独自パイプラインでCUDA 11.8+環境に展開できます。ローカルワークステーション、マネージドKubernetes、サーバーレスGPUバースト向けチュートリアルも揃っています。
deepseek ocrをRAGやドキュメントエージェント、下流分析と組み合わせて手作業レビューを減らしましょう。deepseekocrのロードマップは進化を続けており、低解像度スキャンでの精度を高めつつレイテンシーを抑えた新しいdeepseek-ocrチェックポイントにご期待ください。
GitHubやHugging Face、コミュニティ検証のデータが、deepseekocrのグローバルワークロードでの信頼性を裏付けます。
deepseek ocrは10×圧縮でも損失をほぼゼロに抑えます。20×でも60 %の精度を維持し、コスト重視の取り込みパイプラインに最適です。
Hugging Faceはdeepseek-ocr資産への月間訪問が22.9 Mに達したと報告し、GitHubは471.49 M件のユニークインタラクションを記録しており、本番適性を示しています。
LLM中心の推論により、deepseekocrは図面の説明やレシート注釈、バウンディングボックスのラベリングを、別個のOCR+NLPスタックなしで行えます。
機微な運用ではプライバシーレビューを実施してください。コミュニティのフィードバックは、法務・医療記録での幻覚を最小化する重要性を強調しています。
deepseek ocrはビジョン言語モデルとして動作するため、ベンチマーク評価にはプロンプト設計や後処理メトリクスも含めましょう。deepseekocrの精度を手動サンプリングと合わせて監視し、deepseek-ocrの展開が規制要件を満たすようにしてください。
開発者サンドボックスからエンタープライズ文書インテリジェンスまで、deepseek ocrは迅速に適応します。
画像PDFを検索可能なMarkdownに変換し、脚注抽出や自動要約をdeepseekocrプロンプトとRAGツールチェーンで実現します。deepseek ocrは正規化されたテキストやバウンディングボックス、視覚キューを提供し、検索インデックスの信頼性を確保します。
deepseek-ocrをn8nやカスタムHTTPノードと連携し、GPTやClaude、Geminiによる推論ステップを起動しつつ、構造化テーブル出力を維持します。deepseek ocrが高精度抽出を担い、ボットが意思決定を行う自動チェーンが構築できます。
MITライセンスの重みをプライベートデータセンターで稼働させ、機密契約やID、研究ノートを自社管理下に置きます。deepseekocrのチェックポイントは量子化しやすく、監査に耐えるエアギャップ型deepseek-ocr環境を構築できます。
教育機関はdeepseek ocrと人手レビューを組み合わせて古い雑誌や手書きメモをアーカイブし、転記サイクルを大幅に短縮しています。図書館はdeepseekocrメタデータを活用し、検索ポータルやデジタルヒューマニティーズプロジェクトを推進しています。
Hugging FaceやGitHub、開発者コミュニティのテレメトリが、deepseek ocrが研究リリースから本番OCR基盤へ成長している様子を示しています。
Hugging Faceは公式デモの月間セッションが22.9 M、deepseekocrやdeepseek-ocrを参照するGitHubプロジェクトのビューが471.49 Mを超えたと報告しています。圧縮を意識したOCRへの需要は、レイアウト文脈を保ちながらGPUコストを抑えたい開発者ニーズを示しています。
新しいチェックポイントは「コンテキスト光学圧縮」の方針を継続し、deepseek ocrは10×圧縮でほぼロスレス、20×でも約60 %の忠実度を保ちます。これにより製品チームはリソースを抑えつつ大規模バックログを処理し、下流システムが信頼できる整形テキストを届けられます。
Hacker Newsではdeepseek-ocrホワイトペーパーを分析し、セマンティックトークンプーリングと従来のOCRヒューリスティックを比較する議論が行われています。Redditのr/LocalLLaMAやr/MachineLearning、オートメーションフォーラムには、deepseek ocrをn8nやAirflow、独自ETLに組み込むチュートリアルが並びます。
運用者はdeepseekocrが複雑な表や手書きを処理できる点を評価しつつ、品質ゲートやJSONスキーマ検証、抜き取り監査などのガードレールを推奨しています。共有された教訓は、CRMやBIにデータを渡す前に軽量なレビューを組み合わせて幻覚を排除することです。
アナリストはdeepseek ocrをAzure Document IntelligenceやGoogle Vision API、ABBYYと比較し、オープンモデルがSaaSを置き換えるタイミングを検討しています。OmniAIやAI Advancesのベンチマークは、deepseekocrが表の整列や低照度耐性を改善し、差が急速に縮まっていることを示します。
企業事例では、コンプライアンスアーカイブや物流レシート、医薬ラベリングでdeepseek-ocrが活用されています。チームはvLLMマイクロサービスやFastAPI、n8nテンプレートを組み合わせ、最小限のグルーコードでdeepseek ocr出力をRAG検索やサポート用コパイロット、RPAボットに接続します。
deepseekocrをスタックに組み込む手順を紹介します。
github.com/deepseek-ai/DeepSeek-OCRをクローンし、Python 3.12環境を作成してtorch==2.6.0、vllm==0.8.5、プロジェクト要件をインストールします。必要に応じてflash-attnで推論を高速化できます。
エアギャップ環境ではpip downloadでホイールを準備し、モデル重みをアーティファクトストアにミラーし、チェックサム検証を自動化してdeepseek-ocrの再現性を確保します。
画像ストリーミングにはrun_dpsk_ocr_image.py、長尺PDFにはrun_dpsk_ocr_pdf.pyを利用してください。Transformersユーザーはmodel.infer(... test_compress=True)で圧縮を評価できます。
本番環境ではdeepseek ocrをvLLMマイクロサービスやFastAPIゲートウェイでラップし、GPUワーカーのオートスケール、メトリクス収集、ヘルスエンドポイントを整備して負荷下でも安定運用します。
"<image>\n<|grounding|>Convert the document to markdown."などのテンプレートでレイアウトを維持し、"Locate <|ref|>tax rate<|/ref|>"で特定値を抽出します。
"preserve multi-column format"などのレイアウト指示や"respond in English"といった言語指定を追加し、deepseekocrの出力を安定させましょう。実績のあるdeepseek-ocrプロンプトはバージョン管理で共有しましょう。
幻覚対策の品質チェックを導入し、圧縮率を監視し、コミュニティのIssue Trackerと連携してdeepseek ocrの性能を維持します。
GrafanaやPrometheusにメトリクスを送り、OCR成功率や平均圧縮目標、人によるレビュー割合を追跡してdeepseek-ocrの判断が監査に耐えられるようにします。
deepseek-ocrはGOT-OCR2.0やMinerUといったコミュニティの公開ベンチマークを基盤とし、Vary、PaddleOCR、OneChart、Slow Perception、Fox、OmniDocBenchの評価スイートに感謝しています。
チームはAnna's Archiveや公開された法的文書、企業PDFなどを追加し、自分たちのドメインに適したファインチューニングを行います。ロングテールのサンプルを与えることで、deepseek-ocrはデータドリフトにも強くなります。
test_compress=Trueを有効にし、JSONスキーマ検証を要求し、最終的に正規表現で抽出結果をクロスチェックしてください。重要な業務では人のレビューを挟むと安心です。
コミュニティのプレイブックは2段階フローを推奨します。まずdeepseekocrを実行し、その後LLMで要約し、信頼度スコアと差分可視化を記録します。閾値未満の結果は人間にルーティングし、本番システムに直接入れないようにします。
はい。TinyとSmallは12 GB VRAMで快適に動作し、BaseとGundamは24 GB以上があると効果的です。Linux・Windows・macOS向けのコミュニティガイドも公開されています。
エッジデバイスではTinyチェックポイントを量子化し、TensorRT-LLMやONNX Runtime経由でエクスポートすると、キオスクや産業用スキャナ、ロボティクスでも省電力でdeepseek ocrを提供できます。
公式GitHubリポジトリでPull Requestを送り、Hugging Faceディスカッションでローカルプロンプトを共有してください。deepseekocrは英語と簡体字中国語のドキュメント更新を優先しています。
スクリプトやDockerfile、ワークフローガイドをGitHubやHugging Face、Redditで共有し、deepseek-ocrコミュニティ全体で再現性と導入スピードを高めましょう。